kernel基础知识
纯理论版
内核和操作系统
内核的概念经常会和操作系统一起出现,所以我们首先了解一下内核和操作系统的关系。
操作系统(Operating System,简称 os)是一种管理计算机软硬件资源的系统软件,而 kernel 是 os 最基本的部分,也就是说,两者是包含关系。os 是接口,内核是一个操作系统的核心。
应用程序要运行在满足条件的操作系统之上,而操作系统则是要运行在硬件上的。他们之间的关系如下图:
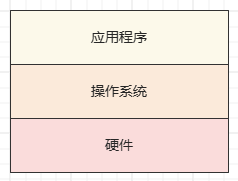
例如我们最常用的 windows 操作系统。一个 windows 系统的电脑拿到手,最直观的就是它提供的界面,和一系列办公套件(office),等等。而我们看不到的计算机默默处理事务的部分就是内核,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统等等,主要功能可以总结为以下三点:
- 控制并与硬件进行交互
- 提供应用程序的运行环境
- 调度系统资源
需要注意,和一般的程序不同,kernel 如果发生崩溃会导致整个系统重启
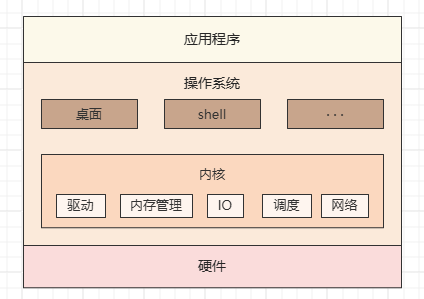
kernel 实际上也是一个程序,用来管理软件发出的数据 I/O 要求,并将这些要求转义为指令,交给 CPU 和计算机中的其他组件处理。
内核架构的分类
内核的架构分为宏内核和微内核两种。
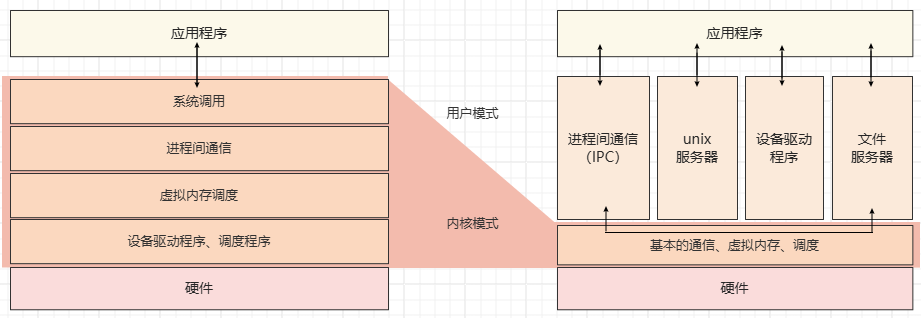
宏内核
宏内核的特点是内核程序是一整个单一的二进制可执行文件,在内核态中以监管者模式(Supervisor Mode)来运行。这些内核会定义出一个高端的虚拟接口,由该接口来涵盖描述整个电脑硬件,这些描述会集合成一组硬件描述用词,有时还会附加一些系统调用,如此可以用一个或多个模块来实现各种操作系统服务,如进程管理、并发控制、存储器管理等。
通俗地说,宏内核几乎将一切都集成到了内核当中,并向上层应用程式提供抽象API(通常是以系统调用的形式)。
Unix就是宏内核的。
微内核
对于微内核而言,大部分的系统服务(如文件管理等)都被剥离于内核之外,内核仅仅提供最为基本的一些功能:底层的寻址空间管理、线程管理、进程间通信等。
windows声称自己使用的是微内核,实际上更接近于二者之间的状态——在内核中集成了部分需要具备特权的服务组件。
分级保护域
分级保护域(Rings)是将计算机不同的资源划分至不同权限的模型。
intel CPU 将 CPU 的特权级别分为 4 个级别:Ring 0、Ring 1、Ring 2、Ring 3。Rings 是从最高特权级(通常被叫作0级)到最低特权级(通常对应最大的数字)排列的,在大多数操作系统中,Ring0 拥有最高特权,并且可以和最多的硬件直接交互(比如CPU,内存)。内层 ring 可以任意调用外层 ring 的资源。
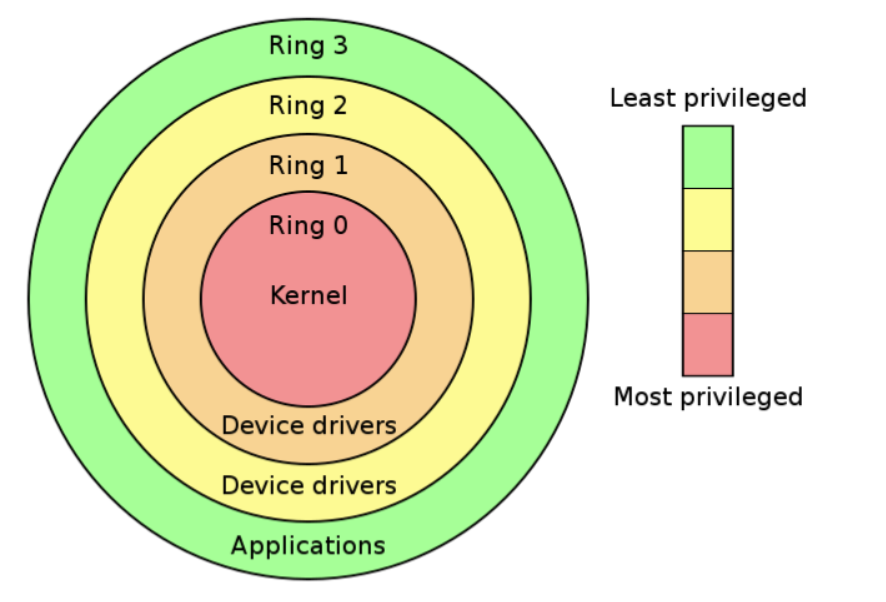
一般来说只用 Ring 0 和 Ring 3 就可以区分(即内核态与用户态),Ring 0 只能被操作系统使用,Ring 3 则所有程序都可以使用。
现代操作系统启动过程概述
当计算机通电后,操作系统会从磁盘上载入第一个扇区执行,之后载入第二引导程序,由第二引导程序来将操作内核载入到内存当中并跳转到内核入口点,将控制权交给内核。
内核在完成一系列的初始化过程之后,会启动一些低权限(ring3)的进程以向我们提供用户界面。
用户空间 & 内核空间
在现代操作系统中,计算机的虚拟内存空间通常被分为两块空间——供用户进程使用的用户空间(user space)与供操作系统内核使用的内核空间(kernel space)
我们之前有了解过虚拟内存的概念,每一个进程都是相似的虚拟内存分配,如下图:
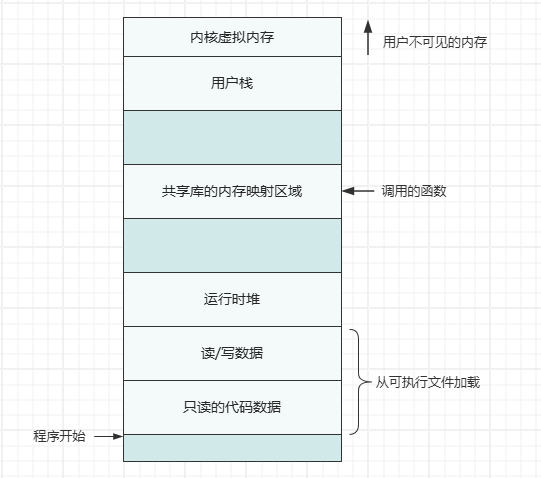
用户态 & 内核态
当程序运行在内核空间时就是用户态,当程序运行在用户空间时就是出于用户态,这是人为划分的。
运行在内核态的函数会和用户态有些许不同,比如 printf -> kprintf、memcpy -> copy_to_user / copy_from_user。内核的动态分配并不会使用用户态的 glibc,它的堆分配器是 SLAB 或 SLUB 。常使用的函数例如:malloc -> kmalloc 、 free -> kfree。
用户态不能运行内核态的函数,同时,为了安全考虑,内核态也只能运行内核态的函数。所以应用程序运行时总会经历无数次的用户态与内核态之间的转换。
当我们要运行一个程序时,本质上是通过操作系统预先运行的用户态进程(如 shell 等)向操作系统发出请求,此时控制权移交内核,内核完成进程内存空间的初始化后再将控制权移交回用户进程。
运行状态之间的切换
进入内核态,本质上其实是将进程的控制权限转交给操作系统内核,当内核完成其工作后控制权又重新回到用户进程。
由用户态进入到内核态主要有以下几种途径:系统调用(int 0x80/sysenter)、异常外设、产生中断。
需要进行下面的操作:
切换GS段寄存器:通过
swapgs切换 GS 段寄存器,将 GS 寄存器值和一个特定位置的值进行交换,目的是保存 GS 值,同时将该位置的值作为内核执行时的 GS 值使用保存用户态栈帧信息:将当前栈顶(用户空间栈顶)记录在 CPU 独占变量区域里,将 CPU 独占区域里记录的内核栈顶放入
rsp/esp保存用户态寄存器信息:通过 push 保存各寄存器值到栈上,以便后续反回用户态
通过汇编指令判断是否为32位
控制权转交内核,执行系统调用
在这里会用到一个全局函数表
sys_call_table,其中保存着系统调用的函数指针
由内核态返回用户态只需要恢复用户空间信息:
swapgs指令恢复用户态GS寄存器sysretq或者iretq恢复到用户空间
进程权限管理
kernel 调度着一切的系统资源,并为用户应用程式提供运行环境,相应地,应用程式的权限也都是由 kernel 进行管理的。
进程描述符
在内核中使用结构体 task_struct 表示一个进程,其中包含着进程的各种信息,包括进程权限的管理。
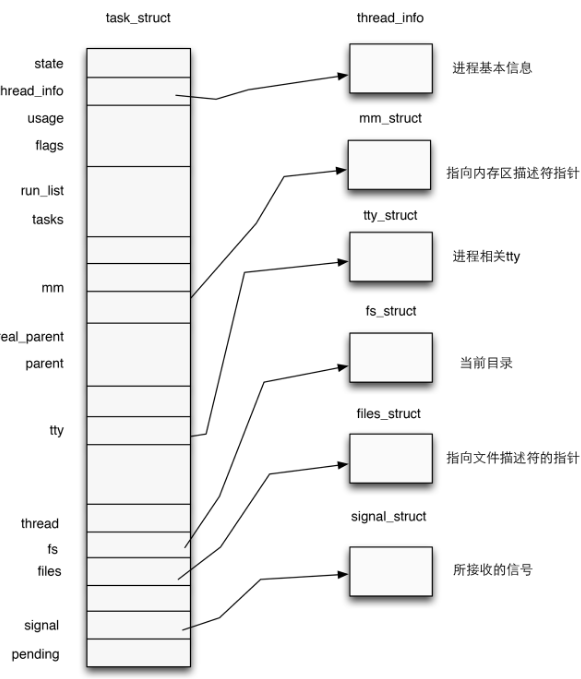
和进程权限相关的部分如下:
1 | |
Process credentials 是 kernel 判断一个进程权限的凭证,在 kernel 中使用 cred 结构体进行标识.对于一个进程,应当有三个 cred:
- ptracer_cred:使用
ptrace系统调用跟踪该进程的上级进程的 cred(gdb 调试便是使用了这个系统调用,常见的反调试机制的原理便是提前占用了这个位置) - real_cred:即客体凭证,通常是一个进程最初启动时所具有的权限
- cred:即主体凭证,该进程的有效 cred ,kernel 以此作为进程权限的凭证
一般情况下,主体凭证与客体凭证的值是相同的
cred 结构体
上面提到的进程权限凭证中有一个指向 cred 的指针,而 cred 本体就是用来管理权限的
1 | |
real UID - 真实用户ID:用来标识一个进程启动时的用户 ID
saved UID - 保存用户ID:标识一个进程最初的有效用户 ID
effective UID - 有效用户ID:标识一个进程正在运行时所属的用户 ID。一个进程在运行过程中的所属用户不是固定的,它可以改变自己的所属用户,因而权限机制也是通过有效用户 ID 进行认证的,内核通过 euid 来进行特权判断;为了防止用户一直使用高权限,当任务完成之后,euid 会与 suid 进行交换,恢复进程的有效权限。
UID for VFS ops - 文件系统用户 ID:标识一个进程创建文件时进行标识的用户ID
看上去大家好像都差不多,实际上,大部分情况下上面四个确实是相同的🤓
用户组ID(GID)也一样,分成四个,和用户 ID 类似。
进程权限改变
因为进程权限是由 cred 结构体来控制的,所以我们只要改变 cred 结构体,就可以改变一个进程的执行权限了。
修改 cred 的函数有下面的两个:
struct cred* prepare_kernel_cred(struct task_struct* daemon):该函数用以拷贝一个进程的 cred 结构体,并返回一个新的 cred 结构体,需要注意的是daemon参数应为有效的进程描述符地址或NULLint commit_creds(struct cred *new):该函数用以将一个新的cred结构体应用到进程
具体的,在 prepare_kernel_cred 函数中,如果我们需要传入的参数 daemon 是 NULL ,就会使用 init 的 cred 来拷贝,而 init 进程拥有 root 权限,也就是说缺省调用 prepare_kernel_cred 函数时,就会获得一个 root 权限的 cred 结构体!
由此可以联想到,只要我们能够在内核空间执行 commit_creds(prepare_kernel_cred(NULL)),那么就能够将当前进程的权限提升到root !
I/O
linux 之下万物皆文件,包括真正的文件、设备、进程甚至是套接字都可以被抽象成文件,以文件的方式进行操作。因为这种统一性,使得所有的读操作都可以通过 read 实现,所有的写操作都可以通过 write 实现。
进程文件系统
进程文件系统(process file system, 简写为 procfs )用以描述一个进程,其中包括该进程所打开的文件描述符、堆栈内存布局、环境变量等等。
进程文件系统本身是一个伪文件系统,通常被挂载到 /proc 目录下,并不真正占用储存空间。我们可以在这个目录下去找到进程的具体信息。
文件描述符 fd
进程通过文件描述符来完成对文件的访问,内核会为每一个运行中的进程维护一个文件描述符表,文件描述符 fd 就是这个表的索引,该表每一个表项都是已打开文件的 file 结构体指针。
file结构体是内核中用来描述文件属性的结构体
每当进程通过系统调用 open 系统调用来打开一个文件,都会获得一个文件描述符,并为该文件创建一个file对象,并把该file对象存入进程打开文件表中(文件描述符数组),以便进程通过文件描述符为连接对文件进行其他操作。
在kernel中有着一个文件表,由所有的进程共享。
stdin、stdout、stderr
每个 linux 进程都应当有着三个标准的 POSIX 文件描述符,对应着三个标准文件流:
stdin:标准输入 - 0stdout:标准输出 - 1stderr:标准错误 - 2
此后打开的文件描述符应当从标号 3 起始
ioctl 系统调用操作设备
ioctl 是linux 系统中专门用于进程和设备之间通信,控制设备输入输出操作的系统调用。
在用户空间实用 ioctl 操作设备的时候,其接口为
1 | |
- fd:文件描述符
- request:请求码,就像系统调用一样,每一个命令都有自己对应的请求码。
对于一个提供了 ioctl 通信方式的设备而言,我们可以通过其文件描述符、使用不同的请求码及其他请求参数通过 ioctl 系统调用完成不同的对设备的 I/O 操作。
保护机制
Linux Kernel 和普通的程序一样,有各种各样的保护机制:
KASLR
内核空间地址随机化(kernel address space layout randomize),和用户态程序的地址随机化原理相同——在内核镜像映射到实际的地址空间时加上一个偏移值,但是内核内部的相对偏移其实还是不变的。
FGKASLR
实际上就是 KASLR 的加强版,以函数粒度重新排布内核代码。
STACK PROTECTOR
类似于用户态的canary,用来检验是否发生了溢出。和用户态类似,内核中的 canary 的值通常取自 gs 段寄存器某个固定偏移处的值。
SMAP/SMEP
SMAP 是管理模式访问保护(Supervisor Mode Access Prevention),SMEP 是管理模式执行保护(Supervisor Mode Execution Prevention),这两种保护通常是同时开启的,用以阻止内核空间直接访问/执行用户空间的数据,完全地将内核空间与用户空间相分隔开。
KPTI
KPTI 即内核页表隔离(Kernel page-table isolation),内核空间与用户空间分别使用两组不同的页表集。
我是参考了这几篇文章进行的学习,如果我的博客有写的不是很严谨或者不详细的地方可以去佬的博客里找找