how2heap深入浅出学习堆利用(一)
还是好好打基础···
以前都是直接拿题来,碰到知识点就去学。然后碰一道题一道题不会,所以就来系统的学一下 how2heap
- 这个实验如果要做的话建议先看一下 malloc 的源码,我就是一开始根本不懂每一步的原理,分析完源码以后豁然开朗了🍿
- 我用来编译实验用例的代码是【PWN】how2heap | 狼组安全团队公开知识库 (wgpsec.org)
fastbin_dup
原理: fastbins 的 double-free 攻击
知识点✨:
- fast bins 为单链表存储,并采用后进先出(LIFO)的原则:后 free 的 chunk 会被添加到链表的尾部,也就是后 free 的 chunk 永远在先 free 的 chunk 的后面。后续 malloc 时会先取出链表尾后面的堆块,也就是最后放进去的那个。
- fastbin 的 double free 检查是:如果要 free 掉的这个 chunk(我们记作chunk-A) 属于 fast bin,就会检查链表中当前最后一个地址是不是即将要释放的 chunk-A 的地址,如果不是,就会执行free chunk的操作,将 chunk-A 的地址链接到链表末端。
- 我们只要保证 fast bins 链表最后一个地址不指向 chunk-A ,就可以多次 free chunk-A,从而实现 double free。
GDB 调试
实例做了下面的几个操作:
- malloc 三个堆块(我们暂时记为1,2,3)
- free 1
- free 2
- 再次 free 1
- 再次 malloc 三个堆块
我们先让程序分配好三个堆块
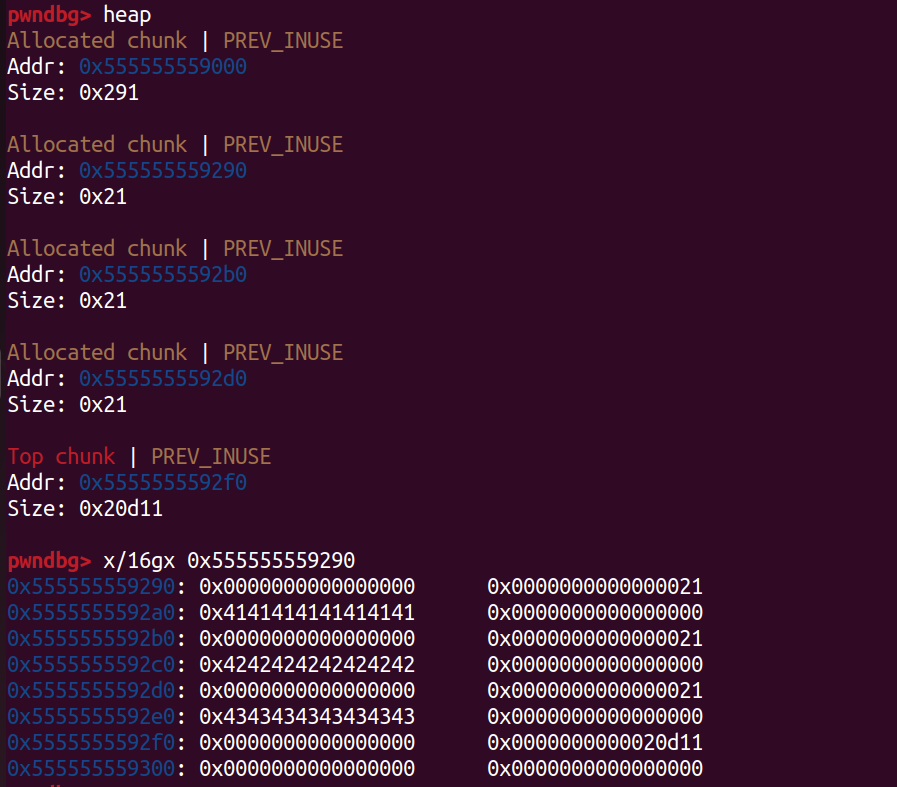
接着 free 掉第一个堆块,它会进入到 fastbin 中
这时我们再次 free (a) 一次,程序就会报错,因为它已经被释放,这个指针指向 free 链表的第一个位置。
那我们该如何去绕过这个检测呢?接下来程序 free(b) ,这时 free 链表第一就是 b ,我们就可以再次 free (a) 了
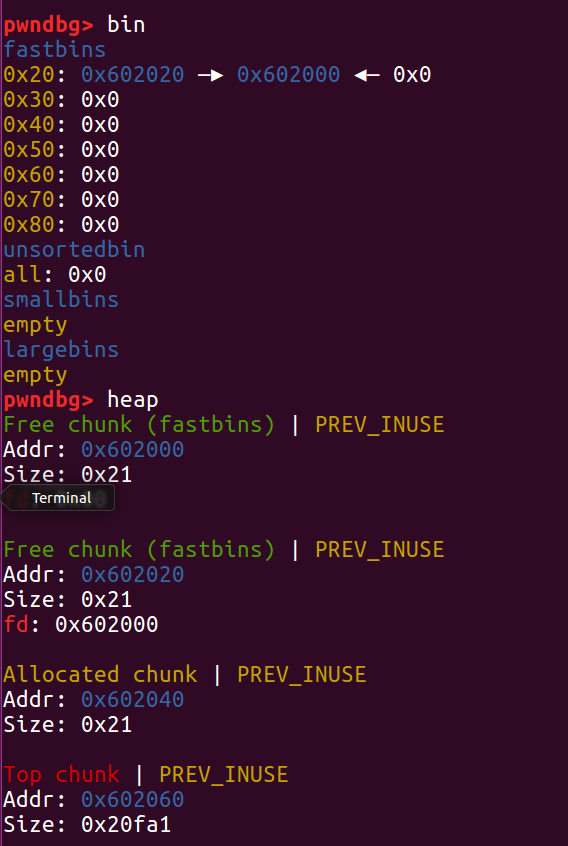
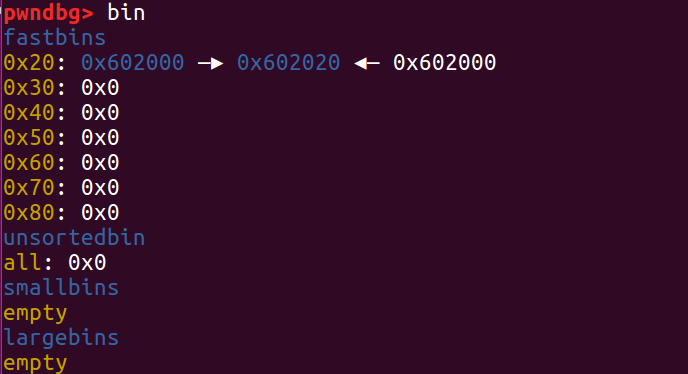
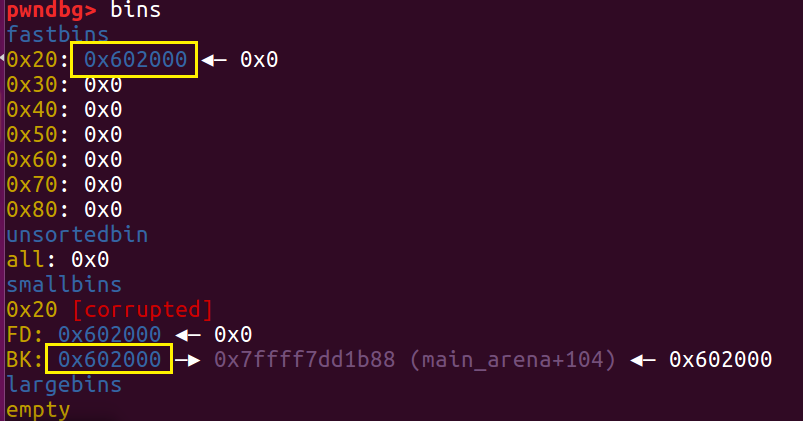
free(a) 之后 fastbin 链表就变成了一个“环形”,这时 free 链表认为它有三块内存 [0x602000, 0x602020, 0x602000]
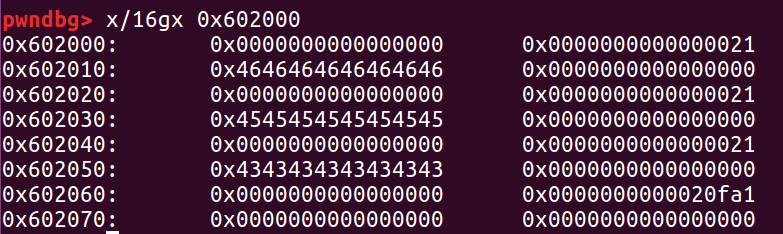
这样的话我们再次 malloc 相同大小的堆块,这个 0x602020 就会被分配两次。我们向里面填充数据可以看到0x4444444444444444 被改成了 0x4646464646464646,是因为后来申请的 f 跟 d 指向同一块内存区域。
总结:
fastbins 的 double-free 攻击,可以泄露出一块已经被分配的内存指针。
由于 free 的过程会对 free list 做检查,我们不能连续两次 free 同一个 chunk 。所以在两次 free 之间,我们只需要增加一次对其他 chunk 的 free 过程,就可以绕过检查顺利执行,这样同一个地址就会在 fast bin 链表中出现两次。随后我们再 malloc 三次,就在同一个地址 malloc 了两次,也就有了两个指向同一块内存区域的指针。
fastbin_dup_into_stack
原理: 这个程序展示了怎样通过修改 fd 指针,将其指向一个伪造的 free chunk,并在伪造的地址处 malloc 出一个 chunk
前面的部分和上一个实验一样,先 malloc 三次然后 free 三次,这时 fastbins 形成了一个循环的指针。
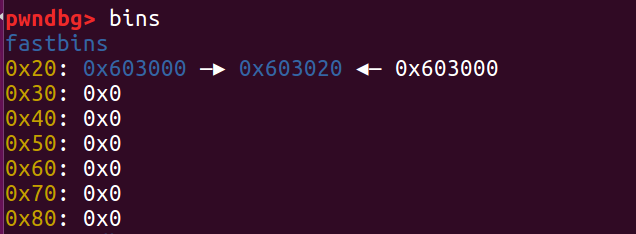
这时我们再 malloc 两次,fastbins 中还剩原本指向 chunk a 的指针。而前两次 malloc 我们已经申请到了同样指向 a 的指针 d
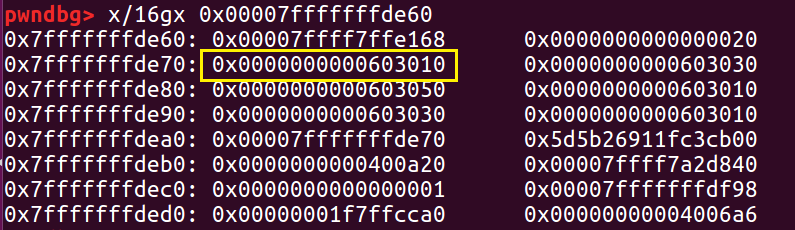
这时,我们查看其内存分布发现它的 fd 指针指向 0x603020
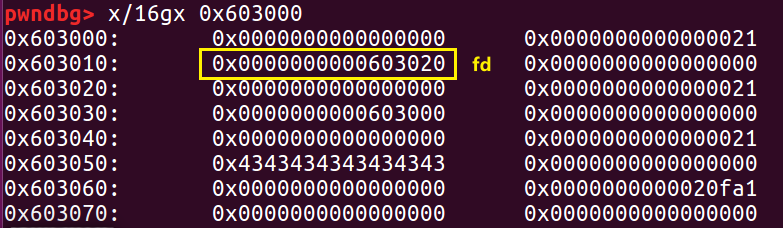
接下来我们修改它的 fd 指针,覆盖 d 的前八个字节(之前有说过,chunk 被使用时,它的 fd 域也会被用来存储信息) 。
stack_var = 0x20; d = (unsigned long long) (((char*)&stack_var) - sizeof(d));
需要注意,我们定义这个 stack_var ,是为了取栈上的地址,栈上第一个参数的地址-8 就是栈的基址。
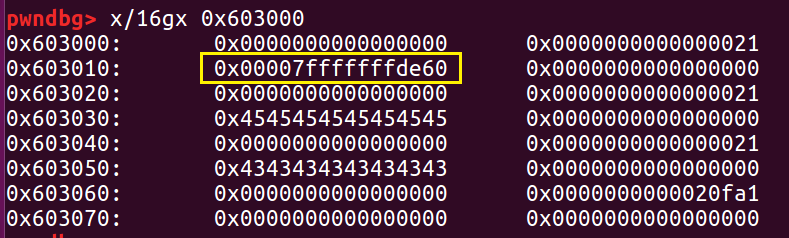
这个时候 fd 就被修改为栈上的地址。
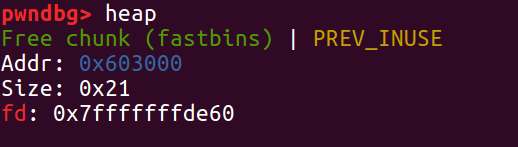
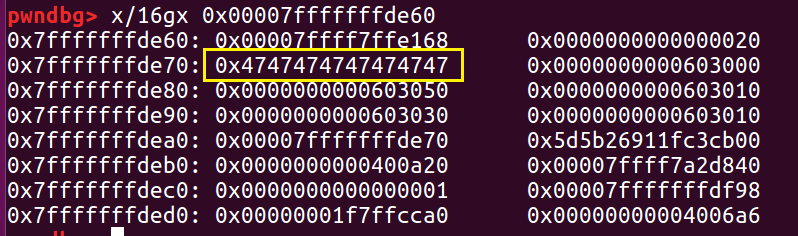
又因为 fastbin 中这时还有一个 a 的地址,所以我们接下来再进行两次 malloc,第一次 malloc 把 double free 的 a 申请掉,第二次 malloc 就会去申请这个栈上的地址,我们将这个栈上的“堆块”记为 S 。
接下来程序向 S 写入数据,可以看出它已经被我们控制了
fastbin_dup_consolidate
原理:使用 malloc_consolidate 机制来绕开 fastbin 对 double free 的检测。
知识点✨:
malloc_consolidate()函数用于将 fast bins 中的 chunk 与其物理相邻的 chunk 合并,并加入 unsorted bin 中。分为高地址(除top chunk)合并和低地址合并。合并后将当前的 chunk 或者 next_chunk 从其所在 bin 中 unlink 出来。
GDB 调试
我们先申请两个 fastbin 大小的 chunk a 和 b,接着 free a。
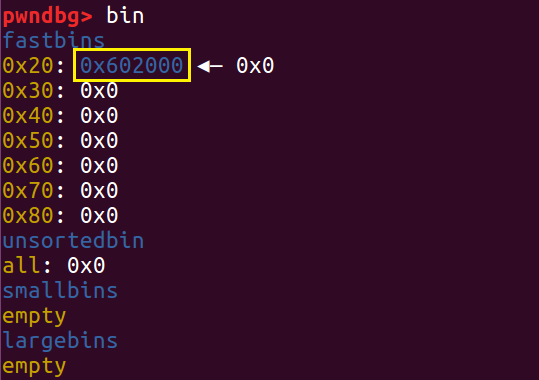
我们再申请一个 largebin 大小的 chunk ,这时程序会调用 malloc_consolidate(),将刚刚 free 的 a 放到 unsorted bin 中,然后经过种种查找遍历(原理详见 malloc 源码分析)再丢进 smallbin 里面。
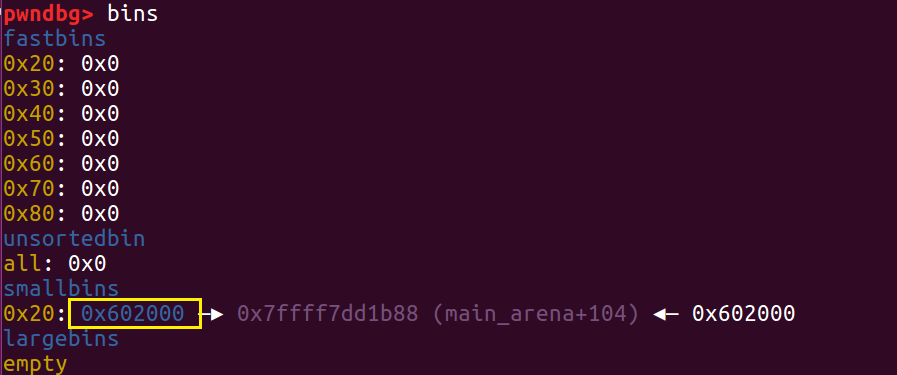
这时 fastbin 链表中的表头就不是 a 啦,我们就可以再一次 free a。
这样之后我们就可以 malloc 两个指向同一地址的 chunk 了。
unsafe_unlink
原理:实现分配的内存里伪造 fake chunk,通过修改 P 的 prev_inuse 位来改变 fake chunk 的状态。free P 时调用 unlink 来合并 P 和 fake chunk,P 的指针会变为 P-0x18。
unlink 通常结合堆溢出漏洞进行利用。通过堆溢出,我们可以申请两个连续的 chunk,通过修改前一个 chunk 的内容溢出到下一个 chunk,实现修改第二个 chunk 的 fd, bk 指针的目的。
涉及到的知识点✨:
inuse chunk 和 free chunk
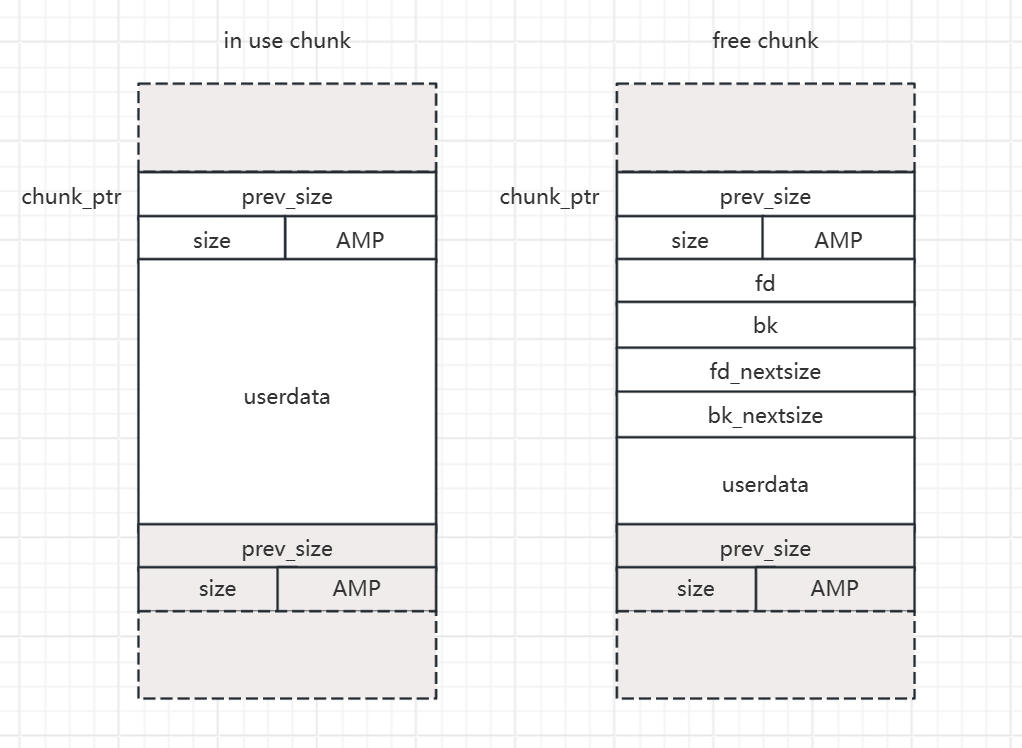
unlink :当我们调用 malloc 去从一块大的堆块中切割小堆块时会调用到
unlink有一个保护检查机制,在解链操作之前,针对堆块 P 自身的 fd 和 bk 检查链表的完整性,即判断堆块 P 的前一块 bk 的指针以及后一块 fd 的指针是否指向 P,后一块堆块的 prev_size 是否等于自身的 size。
首先申请两个 malloc ,我们看内存中的分布如下

我们要实现控制的是 chunk 1,我们利用的指针是 chunk 0。
我们把这个 fake chunk 记为 P 。 (P->fd->bk != P || P->bk->fd != P) == False,接下来我们要处理这个检查。这个检查的 fd/bk 指针都是通过与 chunk 头部的相对地址来查找的,所以我们可以利用全局指针 chunk0_ptr 构造 fake chunk 来绕过它。
1 | |
我们修改 chunk0 的信息,在 chunk0 里面伪造一个 fake chunk。让 fake chunk 的 fd 指针指向 &chunk0_ptr,让 bk 指针指向 &chunk0_ptr,使得 P->fd->bk=P,P->bk->fd=P 。
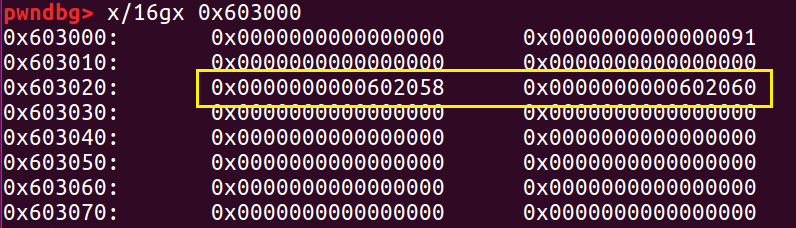
这时我们查看 chunk0 的内存区域,我们就成功地伪造了一个 fd 指针和 bk 指针。
接下来只需要有一个溢出的漏洞,我们就可以改变 chunk1 的 PREV_SIZE 位大小,并把 PREV_INUSE 标志位为 0。在我们的程序中,如果正常的 free(chunk0),那么 chunk1 中的 PREV_SIZE 位是 0x90 ,我们将它改为伪造的 fake chunk 的大小 0x80,并把其标记为空闲。

原本 size 位的 91中的“1”实际上是 PREV_inuse 位
到目前为止,我们的 fake_chunk 里的指针情况如下:
- fd 指针指向 0x602058
- bk 指针指向 0x602060
- 0x602058 的 bk 指向 0x602070
- 0x602060 的 fd 指向 0x602070
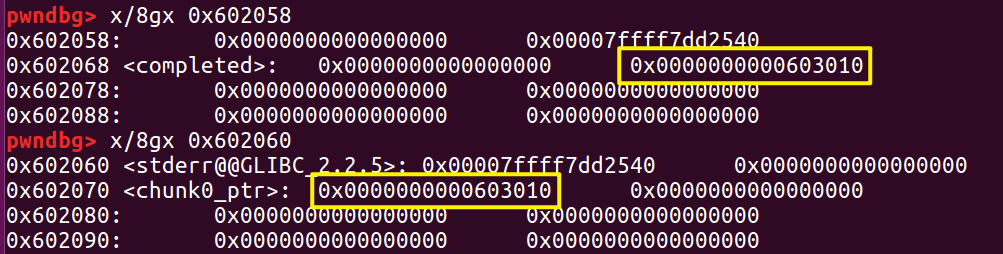
我们保证了一个 fake chunk 与栈上区域的完整的双向链表,
这下我们只要 free(1) ,因为 chunk1 不属于 fastbin,这时我们原本在 chunk0 中的 fake chunk 就会与 chunk1 合并。合并过程调用 unlink() 函数,会发生下面的几个流程,我们分别将他们直接看做具体的内存位置来看:
1 | |
最后实现的结果是:
1 | |
这个时候我们就可以发现,chunk0_ptr 和 chunk0_ptr[3] (fake chunk) 指向的是同一个地址。这样我们就可以利用 chunk0_ptr 覆盖自身来指向任意位置了。
house_of_spirit
到这里终于是看到一个 fastbin 的常见的攻击方法了😀
原理:
House_of_spirit 是利用堆的 fast bin 机制来辅助栈溢出的。如果栈溢出的长度无法覆盖返回地址,但可以覆盖栈上的一个即将被 free 的堆指针。此时就可以利用溢出来将这个指针改写为栈上的地址并在相应位置构造一个 fast bin 块的元数据。接着在 free 操作时,这个栈上的堆块被放到 fast bin 中,下一次 malloc 对应的大小时,由于fast bin的先进后出机制,这个栈上的堆块被返回给用户,再次写入时就可能造成返回地址的改写。
House_of_spirit 利用的第一步是控制修改传给 free 函数的指针,将其指向一个 fake chunk, fake chunk 的伪造是关键。
在这个实验中,我们的 fakechunk 是构建在栈上的有10 个元素的长整型数组,也就就是长度为 80 。这个区域里我们预计设置两个 fake chunk。
在准备阶段,我们可以看到它就是正常的一个栈上的结构:
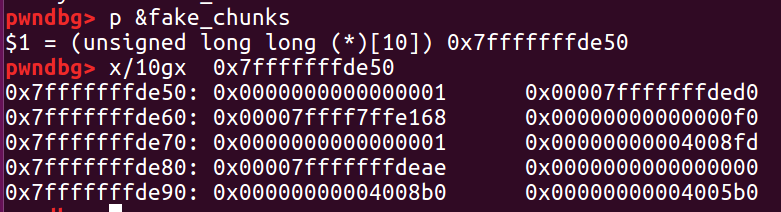
接下来我们构造 fake chunk。
因为我们还没有释放这个 fake chunk 所以只需要设置 size 。
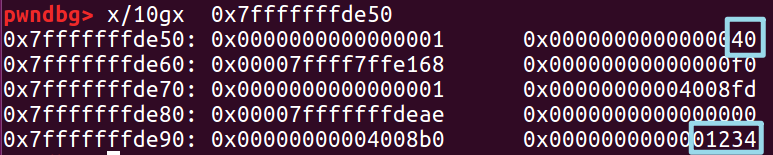
在开始的时候我们申请了一个chunk *a,我们现在假设栈溢出修改了 *a 指向 fake chunk1 ,现在我们 free 掉它.
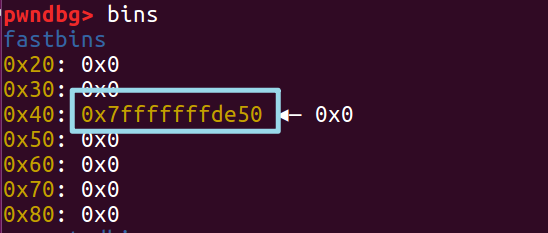
这时我们的 fake chunk 就进入了 bins 中。
当我们再次申请相同大小的堆块时,程序就会把这块内存返回给我们,我们就实现了对这块地址的任意写操作。
对于fakechunk的构造,有以下几点需要注意:
IS_MMAPPED位和NON_MAIN_ARENA位都要为零- 大小要在 32~128 字节之间
🗡️真题实战 hack.lu CTF 2014-OREO
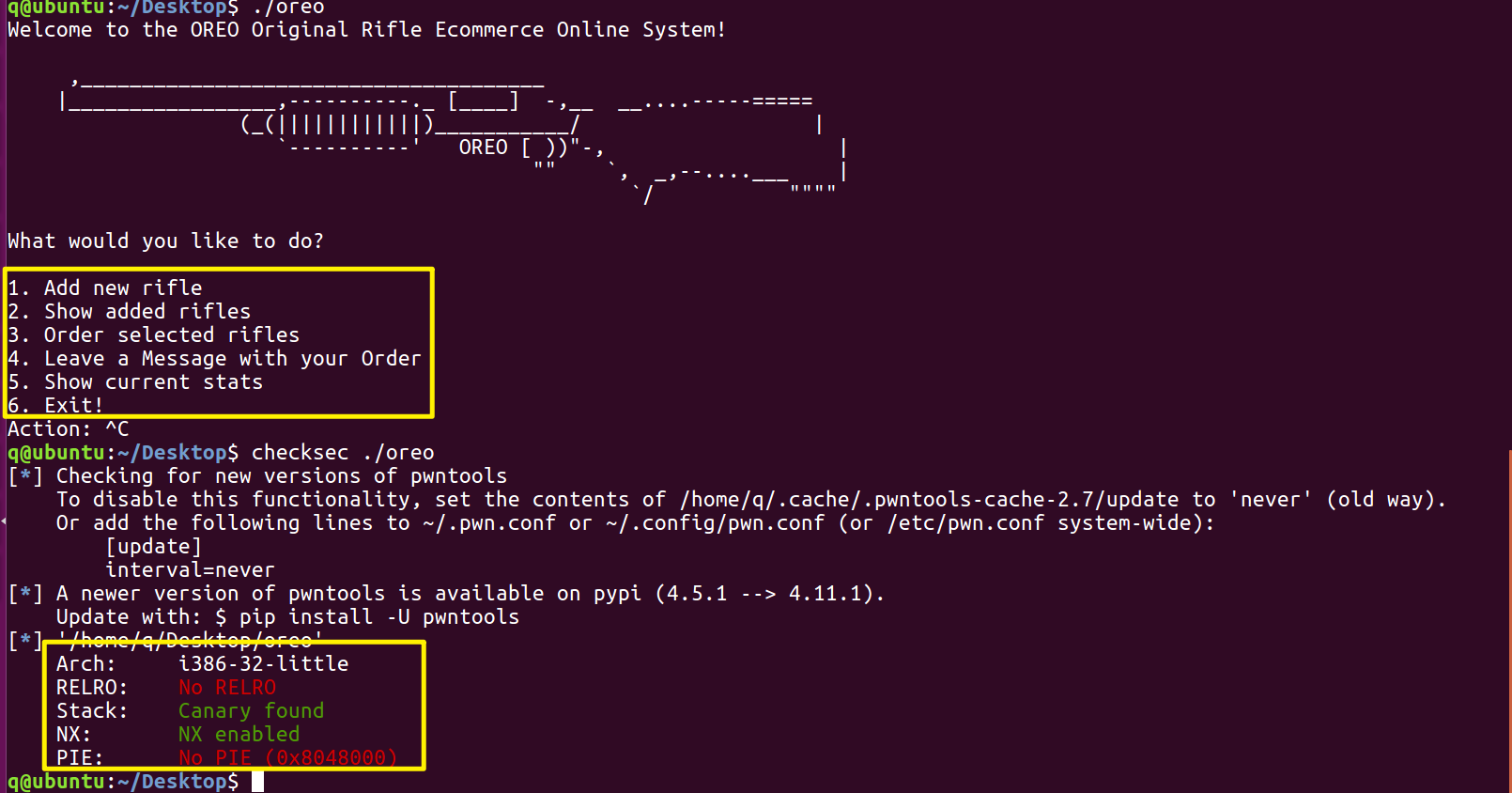
程序菜单所提供的功能,分别对应:
add new rifle:malloc 一个新的堆块show added rifle:输出堆块存储的信息order selected rifle:free 掉在此之前的所有堆块leave a message:根据 bss 段上记录的一个地址,向这个地址进行写入操作。
泄露基地址
我们在 add new rifle 功能函数中可以看出用于存储 rifle 的结构体大致是如下的结构:
1 | |
但是这两个部分都是读取了 56 个字节,可以溢出。
在 show add refle 功能函数中我们可以看出,向用户输出信息是根据每个结点的指针组成的链状结构一一访问。
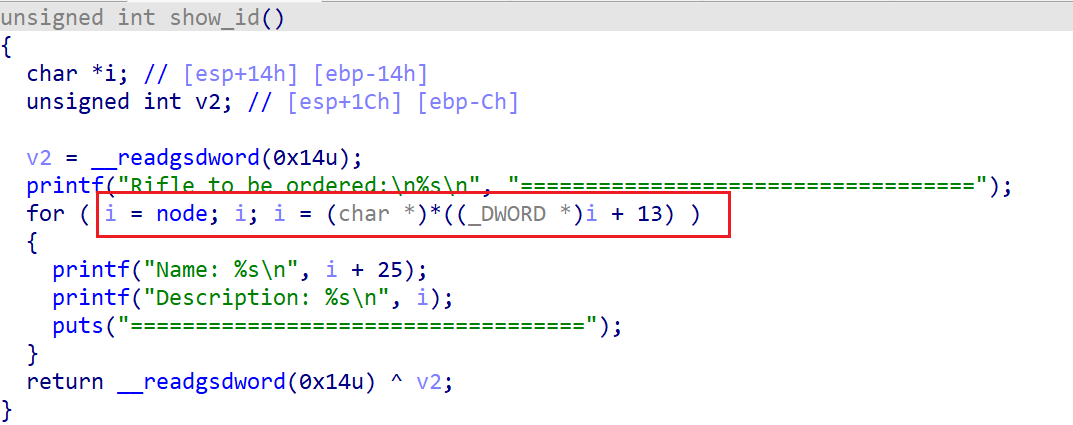
所以我们可以利用这两个函数,在填写 description 时修改第 13 位的 prev 指针指向 puts_got ,再通过 show add refle 泄露地址,从而计算基地址。
House Of Spirit
再回忆一下下完成 House Of Spirit 的条件:
IS_MMAPPED位和NON_MAIN_ARENA位都要为零- 大小在
2 * SIZE_SZ ~ av->system_mem之间 - 地址对齐
再结合本题情况完成对应条件构造:
在
show current stats功能中用到的三个变量在 bss 段写入数据,并且存在一个指针指向0804A2C0。可以在此处构造 fake chunk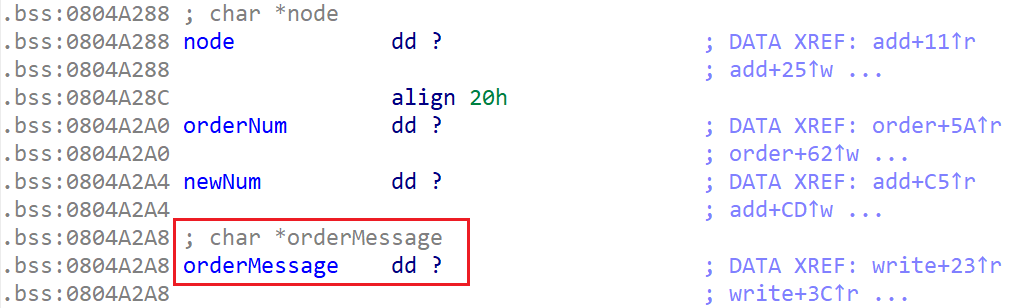
结构体大小是 0x38 大小,所以其对应的 chunk 为 0x40。我们在 fake chunk 中 size 部分对应的是
newNum,而这部分实际存储的内容是我们add的次数,我们可以控制它等于 0x40 同时保证标志位为 0 。而第二个fake chunk的数据区域就会在可编辑的0804A2C0区域,可以直接修改
fake chunk
1 | |
poison_null_byte
我感觉这个实际上就是 off-by-null
原理:伪造一个fake_chunk,并修改物理相邻的下一个 chunk 的 prev_inuse 位为 0 ,引起合并与 unlink ,最后再申请的时候就会从这一块合并的 chunk 中切割,overlap 这一块 chunk 。
知识点:
- chunk 的 size 位低三位为标志位,分别是
NON_MAIN_ARENA、IS_MMAPPED、PREV_INUSE。其中PREV_INUSE表示前面一个内存块是否被使用,0 表示不被使用(被 free了),1 表示正在被使用。 - FD->bk == P && BK->fd == P。
在这里实例中我们申请了四个 chunk,按照申请顺序分别记为 a,b,c 和一个防止堆块与 top chunk 合并的堆块。
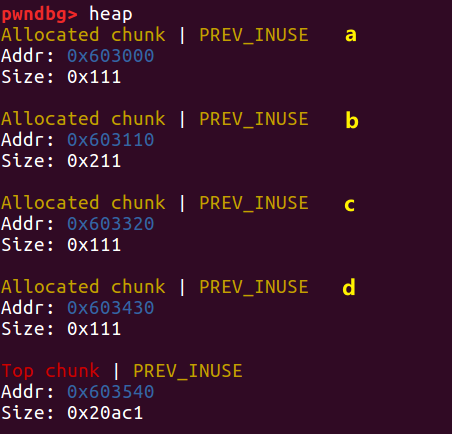
我们想要构造的 fake chunk 在 b 对应的部分,需要用到的只有 chunk b,c 。我们将会在 fake b 里申请两个堆块,其中想要利用的堆块记作 victim。通常 victim 其中包含我们要控制的有价值的指针。
由此,需要在 b+0x200 处伪造一个 fake prev_size:
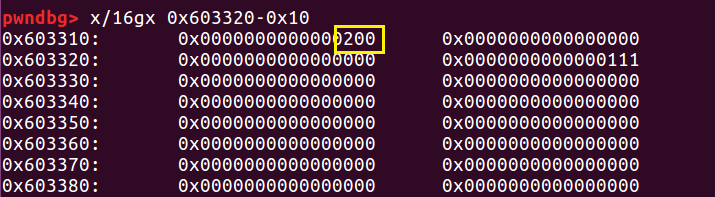
然后 free 掉 b。
假设我们现在在编辑 chunk a 的时候存在 off-by-null 漏洞,我们就可以通过编辑 a 来溢出到 b size 位的标志位,使得其从 211 变为 200。


这时就和前面的操作对应,我们修改 b 的大小为 0x200,那么程序就会去 b+0x200 的地方查找它的 prev_size,而不是去 c 寻找。这样我们就绕过了 chunksize(P) = prev_size(next_chunk(P)) 的检测。
接下来申请一个 0x100 大小的 chunk b1,因为 b 已经被 free 了,所以 glibc 会将 b 进行切割,分出一块 0x100 大小的堆块给 b1,剩下 0xf0 。
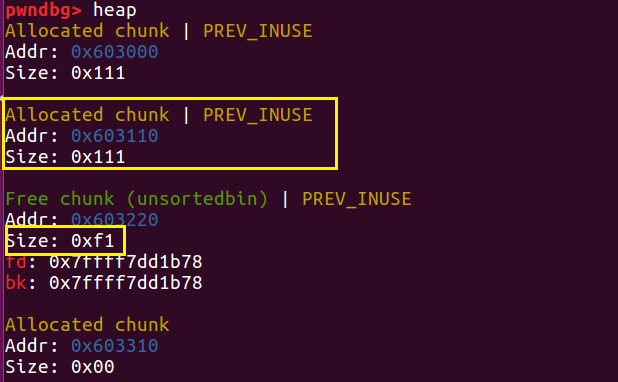
这个时候我们再回到伪造的 0x200 大小的 fake_b 的 prev_size 位变成了 0xf0

接下来再去申请一块小于 0xf0 的堆块记为 victim,这样就会继续分割 b 剩下的那一块
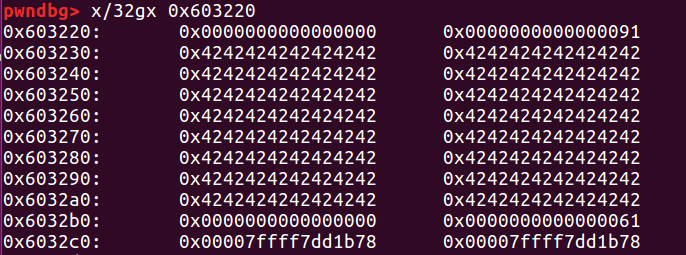
接下来 free 掉 b1 和 c
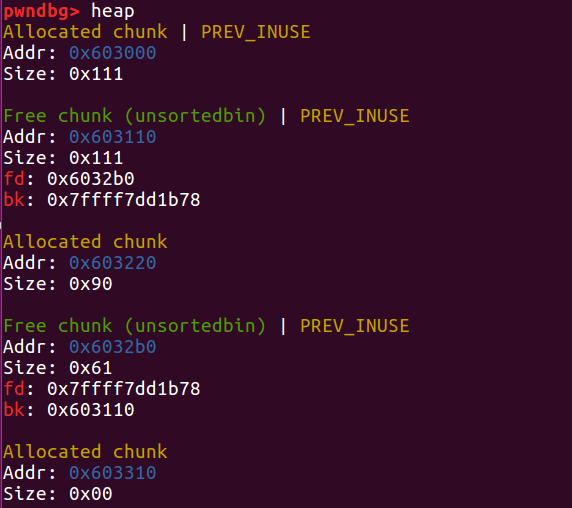
因为 c 的 prev_size 仍为是 0x210,所以会以此去合并原本的 b ,也就是说会将从当前的 b1 到 c 全部的内存区域合并,包含 victim 的内存区域。
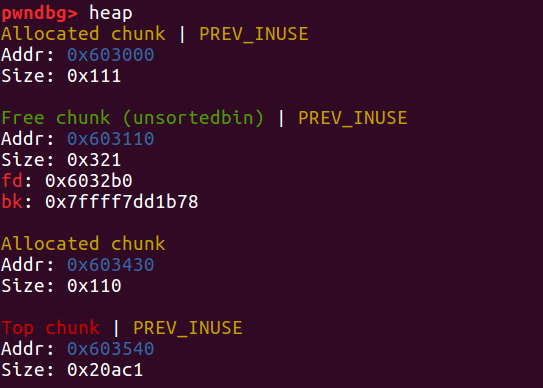
但是对于程序而言我们并没有 free victim 。
接下来再申请一个大的堆块就可以对 victim 进行任意写操作啦。
🗡️真题实战 HITCON CTF 2014-stkof
题目是菜单题的基本逻辑,但是没有为用户输出菜单提示。直接接收用户的输入,可选1-4 实现不同的功能,依次分析各个函数基本对应下面的功能:
- v3 == 1:
malloc(size),同时计数加一,堆块指针存储在全局变量 s 数组 中。size 由用户输入接收。 - v3 == 2:读取 n 长度的字符串存储在最新的堆块当中。其中 n 的大小由用户输入接收,所以可以造成溢出。
- v3 == 3:free 选中的堆块,堆块的选择由用户输入接收。
- v3 == 4:读取 chunk 内容的长度并根据不同情况输出不同内容(没啥用处)
看别的师傅分享的文章时发现了以前没关注过的小 tips :
setbuf() / setvbuf() 函数作用:关闭 I/O 缓冲区
一般的程序为了让程序显示正常,会在代码中通过以下命令关闭 I/O 缓冲区:
2
3>setbuf(stdin ,0);
>setbuf(stdout,0);
>setbuf(stderr,0);本题没有关闭缓冲区,函数运行开始阶段在 fgets() 函数以及 printf() 函数运行的时候,会 malloc() 两块内存区域。
s 是一个存储在 .bss 段的指针,这种指针就是这类 unlink 题目的特征

通用做题流程:
设某一堆块的指针存储在 pchunk 地址处,在该堆块中伪造堆块,填充数据伪造堆头,利用填充堆块内容的函数将该堆块的 fd 和 bk 处分别修改为 pchunk-0x18,pchunk-0x10,然后将相邻的下一堆块的 priv_size 修改为伪造的堆块的大小,堆头 size 修改为相应的大小,然后释放相邻堆块(大小需为非 fastbin )就可以触发 unlink ,将该堆块的指针修改为 pchunk-0x18 了。
先把函数写了:
1 | |
我们申请三个块,第一个用与防止堆块与 top chunk 合并,第二个用来伪造 fake chunk ,第三个用来 free 造成 unlink 。
1 | |
申请之后我们可以看到在 .bss 段就存储着新申请的堆块的信息

因为我们要在 chunk 2 处伪造 fake chunk,然后 free chunk 3 ,所以我们就把存放 chunk 2 地址的地方,即0x602150 设为 ptr,然后进行 fake chunk 的构造以及溢出数据的写入。
现在第二个和第三个 chunk 中的信息如下:
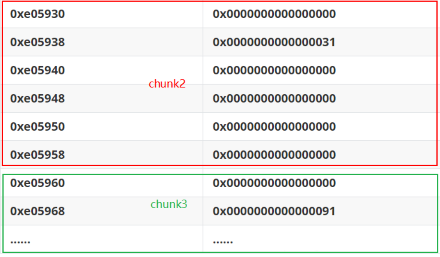
1 | |
执行完这部分的代码后结构会变成下面这样:
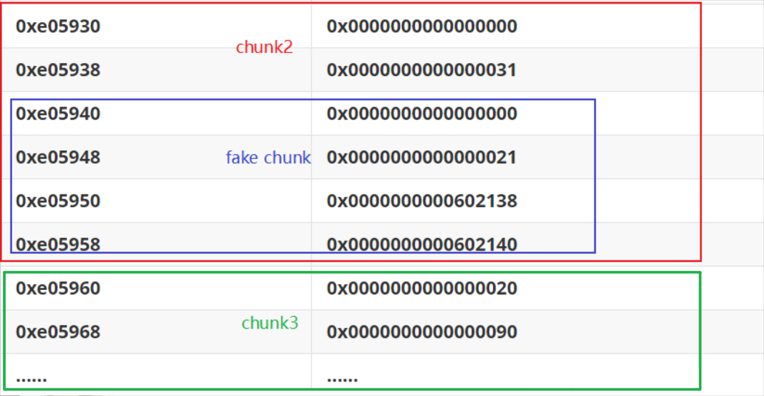
这时 chunk3 的 prev_inuse 位被置为0,表示前一个 chunk 为空闲状态,prev_size 也被改为了对应 fake chunk 的大小。这时我们就可以 free chunk3 了
当我们 free chunk3 时,系统判断前一个 chunk 是否处于空闲状态,我们上面已经通过堆溢出布置好了 chunk3 ,因此系统认为前一个 chunk 处于空闲状态,并通过 chunk3 的位置和 prev_size 定位到前一个 chunk ,即伪造的 fake chunk。随后合并这两个 chunk,这时候要再进行判断,判断的条件就是:
FD->bk=fake chunk && BK->fd=fake chunk
在本题情况中,FD=fake chunk->fd、BK=fake chunk->bk,即 FD=0x602138、BK=0x602140,所以就满足了FD->bk=FD+0x18、BK->fd=BK+0x10 而这两个结果都指向 fake chunk 的地址,因此我们便绕过了检测。
而后会执行 FD->bk=BK、BK->fd=FD,即先把 0x602150 处存储的数据修改为 0x602140 ,然后再改为0x602138 也就是 ptr-0x18 。
0x602150 处本应该存储着 chunk2 的地址,但现在已经被我们改掉了,我们就可以利用这一点,向 .bss 段写入数据,继续进行改写。这样我们就可以通过将指针改写为对应函数的 got 表地址进行泄露和改写,从而 getshell。
1 | |
house_of_lore
原理:这个攻击针对的是 smallbin ,通过修改 smallbin 中的 bk 指针,来申请任意地址。
知识点✨:
- 在分配 smallbin 大小的堆块时,系统会检查链表倒数第二个堆块的 bk 指针是否指向第一块。
GDB 调试
我们主要的目的是伪造一条 small bins 链。
我们首先申请两个 chunk,一个chunk 是我们想要利用的堆块,我们称其为 victim chunk,第二个用于防止与top chunk 合并。
然后,在栈上伪造两个 fake chunk ,让 fake chunk 1 的 fd 指向 victim chunk ,bk 指向 fake chunk 2 ,fake chunk 2 的 fd 指向 fake chunk 1,这样一个 small bin 链就差不多了。
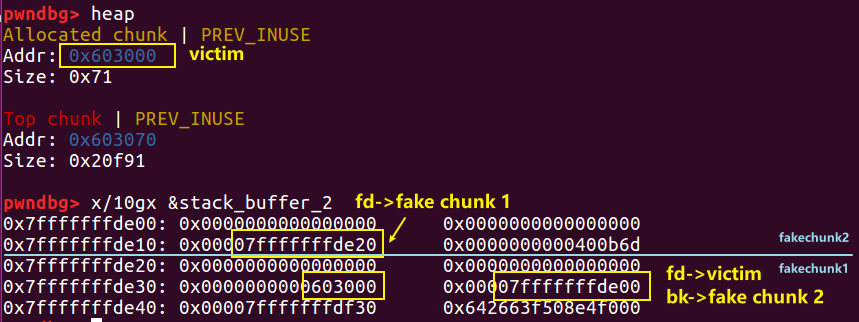
接下来我们 free victim,它会进入 fastbin 。这时候我们再去 malloc 一个大的 chunk ,就会触发 fast bin 的合并,victim 会放到 unsorted bin 中,最终被整理回到 small bin。
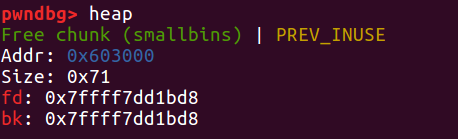
现在我们假设存在一个可以覆盖 victim 的 bk 指针的漏洞,让它的 bk 指针指向栈上。
这样,我们申请一个和 victim 同样大小的 chunk,会把空闲的 victim 分配出去。而后再申请堆块,就会到 victim->bk 处,即栈上去寻找堆块。
这样我们就成功地骗过了 malloc 在栈上分配了一个 chunk。
overlapping_chunks
这一部分在 how2heap 里是分 1 和 2 的,1 的原理是:通过溢出漏洞修改空闲堆块的 size ,将地址相邻的两个 chunk “合并”。 如果 free 后再次申请一个大小匹配的堆块,就会堆块的重叠。
比较简单一看就懂,就略过直接开始 2 了
原理:在释放堆块之前修改它的 size 大小,等它被释放后,错误地修改下一个 chunk 的 prev_size,导致中间的chunk 强行合并。
GDB 调试
我们在本次实验中共分配五个堆块,其中第一个堆块用于模拟溢出漏洞来改写第二个堆块的数据,我们目标重叠的部分是第二至第四个堆块,第五个堆块用于防止与 top chunk 合并。
我们先 free chunk 4
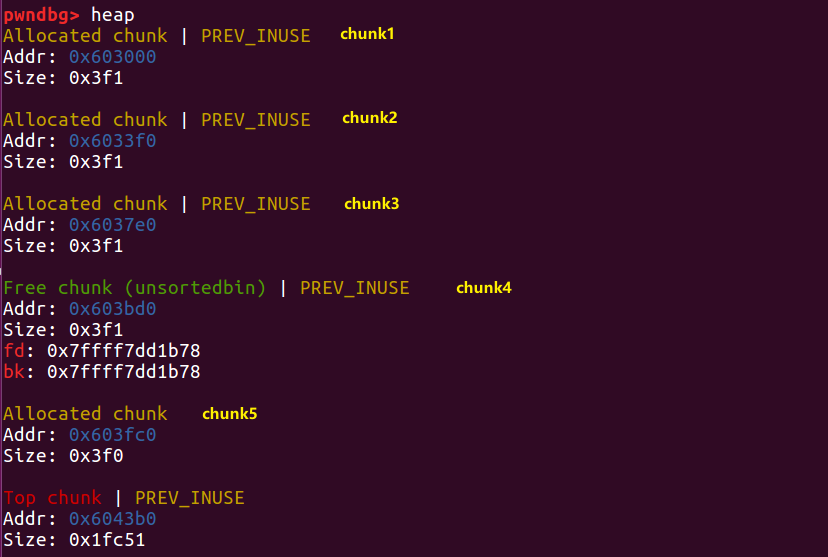
接下来,我们利用 chunk1 的溢出漏洞来改写 chunk2 的 size 值。将 size 改为 chunk2 和 chunk3 的大小之和,在本次实例中就是 0x3f0+0x3f0+0x1=0x7e1
这时我们再 free 2,根据这个被修改的 size 值,程序会以为 chunk 2 加上 chunk 3 的区域都是要释放的,就会错误地修改了chunk 5的 prev_size 。
接着,它发现紧邻的一块chunk 4也是 free 状态,就把它俩合并在了一起,组成一个大free chunk,放进unsorted bin中。
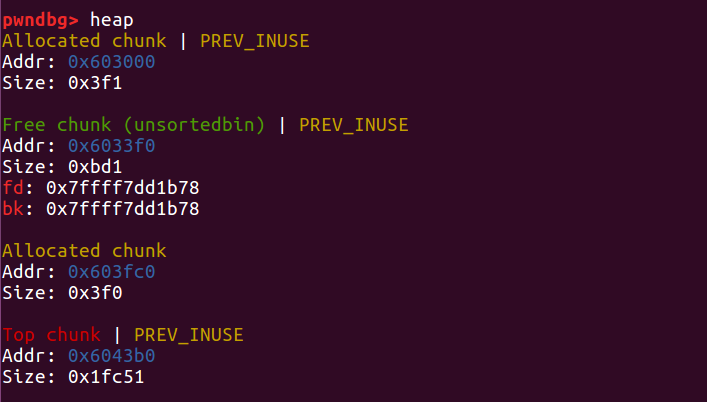
这样,我们就对 chunk3 造成了重叠,可以改写其中的内容了。
🗡️真题实战 Hack.lu CTF 2015 Bookstore
题目是一个订书系统,选项1-5 对应 1、2 编辑订单信息,3、4删除订单信息,5 提交订单信息。
其中1、2 的编辑功能用同一个函数实现,存在溢出漏洞
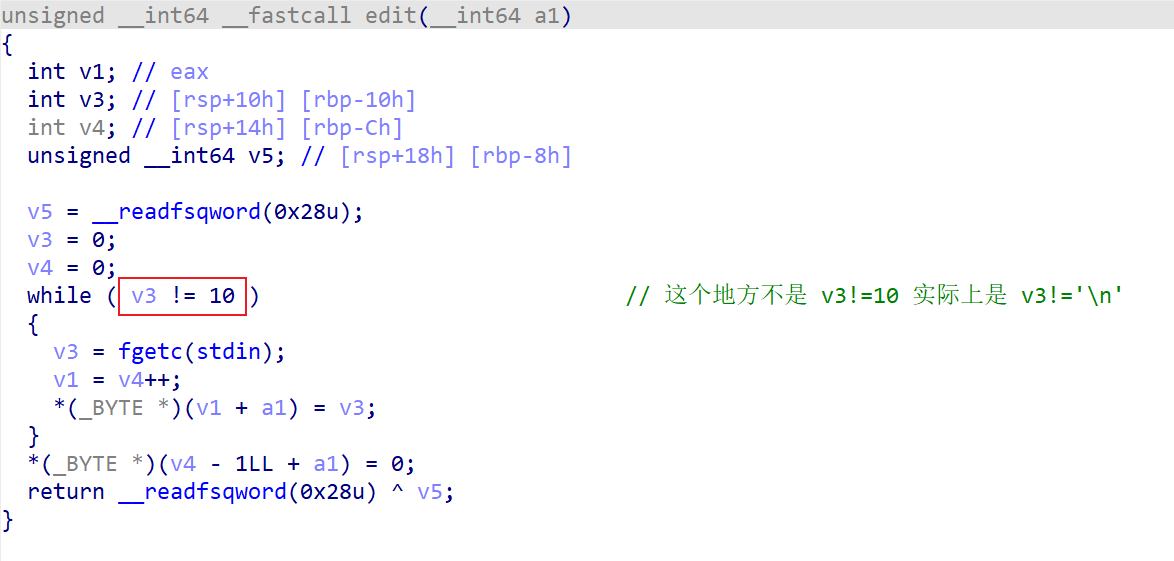
删除订购单是 free 掉了对应的指针,没有把指针指针置为 NULL,存在 UAF 漏洞。
最后提交功能中有格式化字符串漏洞,但是这个漏洞在 submit 功能中,只能利用一次。
- 首先考虑如何利用格式化字符串的漏洞:
我们必须得要控制 dest 的内容才能进行漏洞的利用,那么该如何控制呢?程序最开始的时候分配了三个连续的堆块 v6、v7 和 dest,我们可以通过溢出 v7 来修改 dest 的内容。但是最后会被改写为固定的内容 “Your order is submitted”。
真奇怪我看花眼也没看出来哪里给它赋值了
在最后执行 submitted 的时候会申请一个 v5 ,这个堆块的指针是不确定的,我们可以从 top chunk 里重新分配,也可以 free 掉 v6 、v7,从他们当中分配。这样,我们就可以利用 overlapping ,利用 v7 实现 dest 部分的堆重叠,从而在 submitted 时改写 dest 。
- 因为我们首先需要利用格式化字符串泄露基址,然后需要再利用一次去改写地址,所以接下来考虑如何多次利用格式化字符串:
在接收用户选择输入时,允许用户输入 128 长度的字符串,但是长度不够去利用栈溢出到返回地址,所以我们需要利用其他的方法。
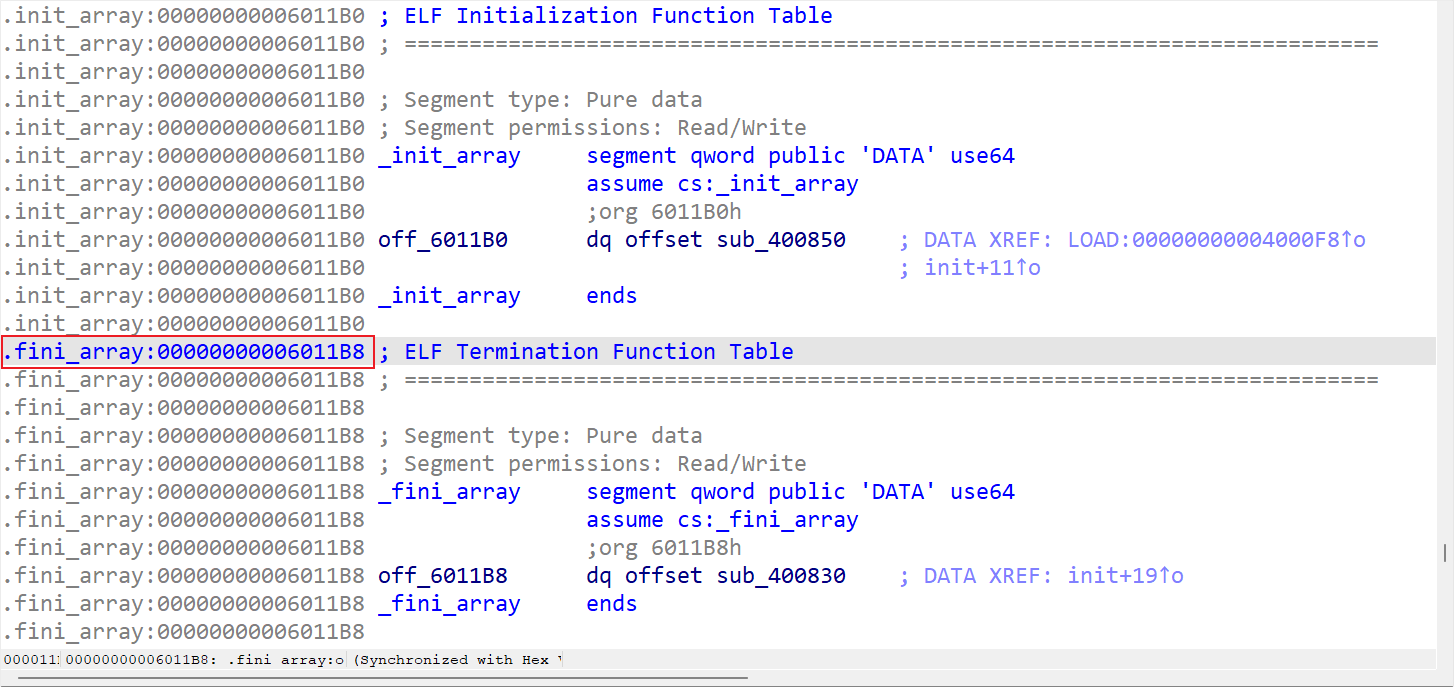
我们需要用到另外一个知识点:程序退出后会执行 .fini_array 地址处的函数,不过只能利用一次。
中插知识点之 .init_array 和 .fini_array 节!
大多数可执行文件是通过链接 libc 来进行编译的,因此 gcc 会将 glibc 初始化代码放入编译好的可执行文件和共享库中。 .init_array和 .fini_array 节(早期版本被称为 .ctors和 .dtors )中存放了指向初始化代码和终止代码的函数指针。
.init_array 函数指针会在 main() 函数调用之前触发。这就意味着,可以通过重写某个指向正确地址的指针来将控制流指向病毒或者寄生代码。 .fini_array 函数指针在 main() 函数执行完之后才被触发,在某些场景下这一点会非常有用。例如,特定的堆溢出漏洞(如曾经的 Once upon a free())会允许攻击者在任意位置写4个字节,攻击者通常会使用一个指向 shellcode 地址的函数指针来重写 .fini_array 函数指针。
对于大多数病毒或者恶意软件作者来说, .init_array 函数指针是最常被攻击的目标,因为它通常可以使得寄生代码在程序的其他部分执行之前就能够先运行。
我们可以利用如下代码自己实验一下 .ini_array 和 .fini_array 的指针属性:
1 | |
我们执行这个程序,并查看其 .init_array 和 .fini_array 的地址
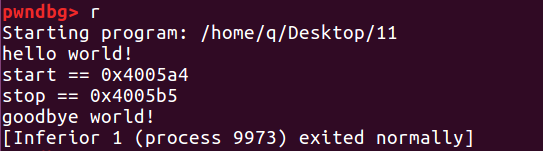

我们可以查看 .init_array 和 .fini_array 地址处存储的指针:

.init_array 存的 0x400540 是 frame_dummy 函数地址(可以在 ida 里面查看),0x4005a4 是我自己定义的 start 函数的地址,也就是说 main 函数开始之前会先执行 frame_dummy 函数和 start 函数。
.fini_array 存的 0x400520 是 do_global_dtors_aux 函数地址,0x4005b5 是自己定义的 stop 函数的地址,也就是说 main 函数结束之后会执行 do_global_dtors_aux 函数和 stop 函数。
去除我们自己定义的属性,此时 .ini_array 和 .fini_array 都只有一个函数指针,对应的 .ini_array 是 frame_dummy 函数地址,fini_array是 __do_global_dtors_aux 函数地址。
知识点结束!
所以我们可以利用第一次格式化字符串将 .fini_array 地址处的函数修改成 main 函数的地址,使程序重新回到 main 函数。除此之外,我们还需要泄漏 libc 地址,再进行 shellcode 的构造这样就是总共利用三次格式化字符串。
我们可以直接在 ida 里面看到 .fini_array 的地址是 0x6011B8:
新的问题来了,怎么把 .fini_array 输入进栈并确定它与 printf 的偏移?同一个函数的栈空间是固定的,我们只需要确定偏移,只需要利用前面的 0x80 的空间,我们可以将 .fini_arry 输入到 s 里然后通过调试确定偏移。

断点打在 printf(dest) 处,可以得出我们输入的 s 在栈上的偏移是 12。
除了 fini 的偏移,我们还需要确定 libc 基址的偏移:
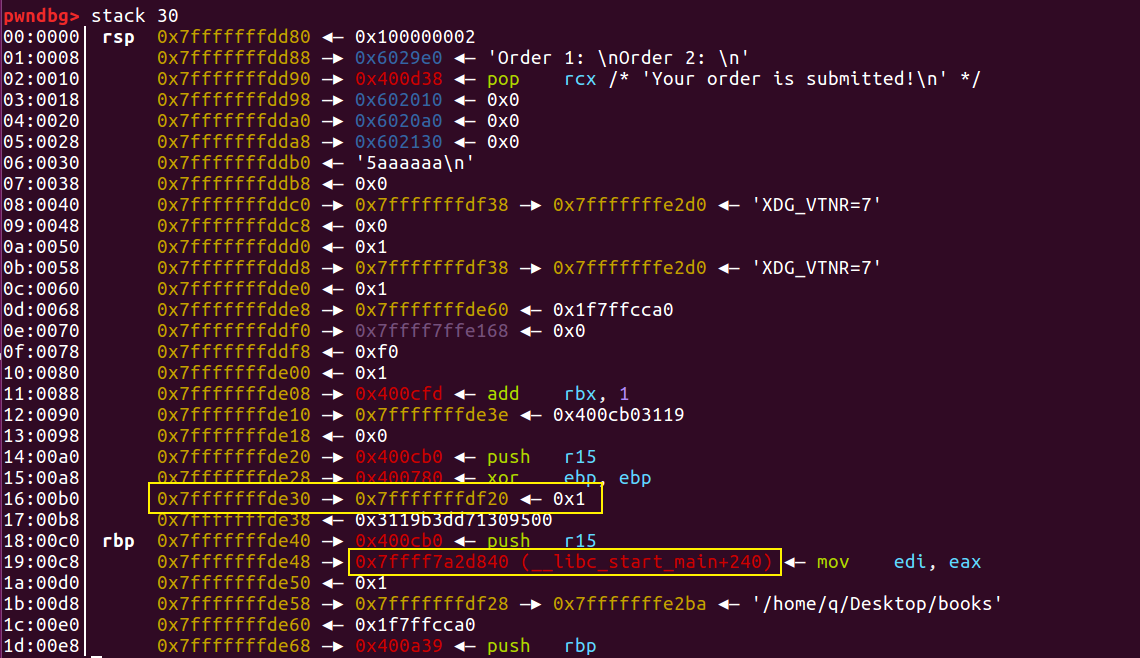
这个栈地址始终指向比自己低 0x10 字节的栈地址,而且指向的栈地址和返回地址也有固定的 0x28 的偏移,所以我选择用格式化字符串泄漏这个栈地址,但是这里还有一个问题:
我们在填充格式化字符串漏洞时,也需要考虑 submitt 函数的功能。我们现在覆盖用 v7 覆盖了 dest 部分,所以输出的字符串将是:
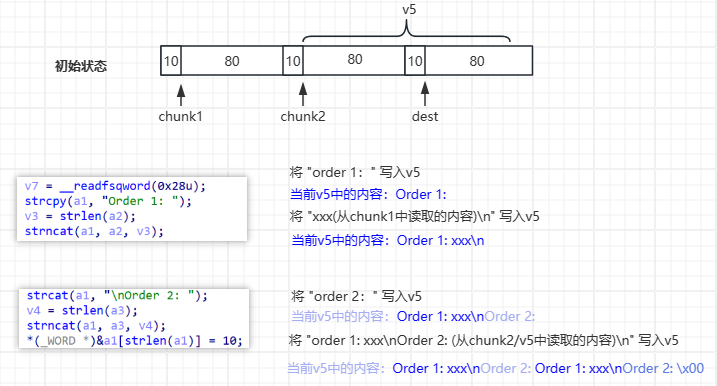
由上图可以看出,我们可以控制的部分是 chunk1 的内容,我们想要控制格式化字符串部分在 dest 指针处,可以控制 chunk1 的内容长度,让其第二次被写入 v5 时刚好重叠在 dest 的位置。
也就是:
size(Order 1: + chunk1 + '\n' + Order 2: + Order 1:) = 0x90
size(chunk1) = 0x90 - 28 = 0x74
所以我们构造 chunk1 中的内容的时候只要使其中非 0 字符串的个数达到 0x74 就行了。
综上!
这道题对我来说好难啊😢对着别人的 wp 磕了两天才嗑明白,格式化字符串的部分还是有些生疏了
1 | |