堆漏洞利用(一)
堆漏洞的利用姿势,赶紧来学习一下吧!!
这个人发什么疯
如果没有特殊说明,环境为 ubuntu16 libc2.23 64位
这个网址可以查看源码 :malloc.c - malloc/malloc.c - Glibc source code (glibc-2.23) - Bootlin
堆溢出
介绍
堆溢出是指程序向某个堆块写入的字节数超过了堆块本身可以使用的字节数,因而导致了数据溢出,并覆盖到了物理相邻的高地址的下一个堆块。
堆溢出的前提是:
- 程序向堆上写入数据
- 写入的数据大小没有被良好的控制
堆溢出和栈溢出、BSS段溢出相似,是一种缓冲区溢出。但是与栈溢出不同的是,对上并没有返回地址这样的可以让攻击者直接控制执行流程的数据,因此在堆溢出的利用中,我们无法通过控制EIP来控制程序。
但我们可以利用与堆相关的数据结构哇,我们的利用策略如下:
覆盖与其物理相邻的下一个 chunk 的内容
prev_size
size,低三位的比特位数据,以及堆块真正的大小
NON_MAIN_ARENA
IS_MAPPED
PREV_INUSE
the true chunk size
chunk content,改变程序的执行流
利用堆的机制实现任意地址写入或者控制堆块中的内容,从而执行程序的控制流。
举个栗子:
1 | |
我们输入A*100,就可以把相邻的堆覆盖掉
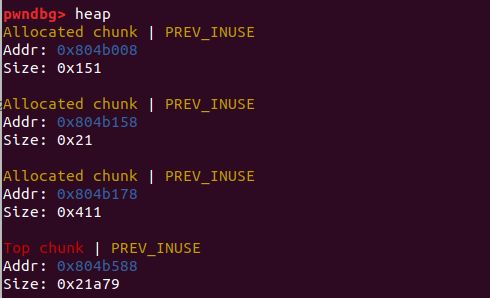

利用步骤
寻找分配函数
通常来说,堆通过 malloc 函数分配,在某些情况下也会通过 calloc 函数分配。这两个函数的区别就是 calloc 在分配后会将空间全部初始化为0。
1 | |
除此之外,还有一个 realloc 分配方式,用于将目标内存扩大。realloc 函数可以身兼 malloc 和 free 两个函数的功能。
1 | |
具体操作:
如果 realloc 的 size 不等于 prt 的 size :
- 申请 size > 原来的 size
- 如果 chunk 与 top chunk 相邻,直接拓展这个 chunk 到新的 size 大小
- 如果 chunk 与 top chunk 不相邻,相当于
free(ptr); malloc(new_size)
- 申请 size < 原来的 size
- 如果相差不足以容纳一个最小的 chunk,(64 位下 32 个字节,32 位下 16 个字节),则保持不变
- 如果相差足够容纳下一个最小的 chunk,就切割原本的 chunk,free 掉后半部分
- 申请 size > 原来的 size
如果 realloc 的 size 等于 0,相当于
free(prt)如果 realloc 的 size 等于 prt 的 size,那计算机将不进行任何操作
寻找危险函数
其实就是栈溢出的时候我们利用的那一批危险函数。常见的危险函数如下
- 输入
- gets,直接读取一行,忽略
'\x00' - scanf
- vscanf
- gets,直接读取一行,忽略
- 输出
- sprintf
- 字符串
- strcpy,字符串复制,遇到
'\x00'停止 - strcat,字符串拼接,遇到
'\x00'停止 - bcopy
- strcpy,字符串复制,遇到
确定填充长度
计算我们开始写入的地址与我们所要覆盖的地址之间的距离。需要注意的是,malloc参数并不等于实际堆块分配的大小,我们之前提到,在实际的内存分配中需要保证chunk 大小是对齐的(字长的两倍)。
并且也并不是机器分配的chunk都是用户可以使用的用户区域,chunk_head.size = 用户区域大小 + 2 * 字长
就比如我们使用 malloc(24) ,在 64 位的系统中申请 24 字节的 chunk 。但由于需要保证内存对齐,系统会向上取整到 32 字节。在分配出来的32字节中,又有两个机器字长也就是 16 字节的头部不能供用户使用,所以实际上我们申请 24 字节的字段,实际上用户可以使用的 chunk 为 16 字节。
但是这个堆块仍然可以储存24字节的数据,因为它可以使用下一个 chunk 的 pre_size 字段,正好 24 个字节( off-by-one 漏洞就是这么来的)。
Off-By-One
严格来讲 off-by-one 也是一种溢出的操作,但是 off-by-one 特指程序向缓冲区中写入时,写入的字节数超过了这个缓冲区本身所申请的字节数并且只越界了一个字节的溢出利用。
原理
off-by-one 是单字节溢出,这种漏洞的产生往往与边界验证不严和字符串操作有关,当然也不排除写入的 size 正好就只多了一个字节的情况(就像上一个 malloc(24) 的例子)。
其中边界验证不严谨主要有以下几种可能:
- 使用循环语句向堆中写入数据时,循环次数设置错误
- 字符串操作不正确
利用思路
溢出字节为可控制字节
通过修改内存块的大小造成块结构之间的重叠,从而泄露其他块数据,或是覆盖修改其他块数据。
溢出字节为NULL字节
在 size 为 0x100 的时候,溢出 NULL 字节可以使得 prev_in_use 位被清,这样前块会被认为是 free 块。
- 使用 unlink 进行处理
- 这时
prev_size域就会启用,可以伪造prev_size,从而造成块之间发生重叠。此方法的关键在于 unlink 的时候没有检查按照prev_size找到的块的大小与prev_size是否一致。
在glibc2.28及以前的版本中都是可以使用的,最新版本中已经添加了对应的检查方法。
🌰:
栗子1:
导致 off-by-one 漏洞的一个原因就是输入的边界检查不清,以下是一个栅栏错误:
1 | |
如上,我们自己写的 my_gets 函数实际输入 size+1 位数据,造成了 off-by-one 溢出。
我们使用 gdb 对程序进行调试,查看在进行输入分配的堆块为两个十六字节的堆块:

连续输入17个1,会发现覆盖到了下一个 chunk 的 prev_size 字节。

栗子2:
导致 off-by-one 的场景就是字符串操作了,常见的原因是字符串的结束符计算有误
1 | |
这个程序乍一看没有任何问题,但是我们需要注意到的是,strlen 的长度计算方法和 strcpy 复制时的长度是不一样的。strlen 计算ASCII 字符串的长度,它在计算长度时是不会把字符串结尾的 ‘\x00’ 计算在内的,但是 strcpy 在复制字符串的时候会拷贝字符串的结束符 ‘\x00’ 。这就导致我们实际上是向chunk1 中写入了25字节。
在strcpy命令执行之前我们的堆结构如下:
1 | |
执行后就会发现它覆盖了下一个堆块的低字节(小端序):
1 | |
(为什么没有截图,因为这玩意我都复现不成功😅)
这个漏洞在2.29之后就不能利用了,因为glibc更新以后增加了检查的代码。
Chunk Extend and Overlapping
这种攻击目的在于将一个chunk块的可控区域衍生到与其相邻的一个或者多个chunk块中。通过这种攻击方式,我们可以修改到不属于本chunk块的内容。通过 extend 可以实现 chunk overlapping 的效果。
一般来说这种技术并不能直接控制程序的执行流程,但是可以控制chunk 中的内容。如果chunk 中存在字符串指针、函数指针等,就可以利用这些指针来进一步进行信息泄露和程序执行流程。
原理
chunk extend 技术能够产生的原因在于 ptmalloc 在对堆 chunk 进行操作时使用的各种宏。
获取当前 chunk 块大小的操作
1
2
3
4
5
6/* 仅用户空间部分的大小 */
#define chunksize(p) (chunksize_nomask(p) & ~(SIZE_BITS))
//SIZE_BITS 在这里是一个代表堆块大小的标志位掩码
/* 完整堆块的大小 */
#define chunksize_nomask(p) ((p)->mchunk_size)获取下一个 chunk 块地址的操作,即使用当前块指针加上当前块大小
1
#define next_chunk(p) ((mchunkptr)(((char *) (p)) + chunksize(p)))获取前一个 chunk 块信息的操作,其中堆块地址的计算是由当前 chunk 地址减去前一个 chunk 的大小
1
2
3
4
5/* 前一个堆块的大小 */
#define prev_size(p) ((p)->mchunk_prev_size)
/* 前一个堆块的地址 */
#define prev_chunk(p) ((mchunkptr)(((char *) (p)) - prev_size(p)))判断当前堆块是否被使用,即查看下一 chunk 的 prev_inuse 域,而下一块地址又如我们前面所述是根据当前 chunk 的 size 计算得出的
1
2#define inuse(p)
((((mchunkptr)(((char *) (p)) + chunksize(p)))->mchunk_size) & PREV_INUSE)
通过上面的几个宏我们可以看出, ptmalloc 通过 chunk header 的数据来判断 chunk 的使用情况和对 chunk 前后进行定位。
而我们的 chunk extend 就是通过控制 chunk header 即 size 和 pre_size 域来实现跨越块操作导致 overlapping。
示例
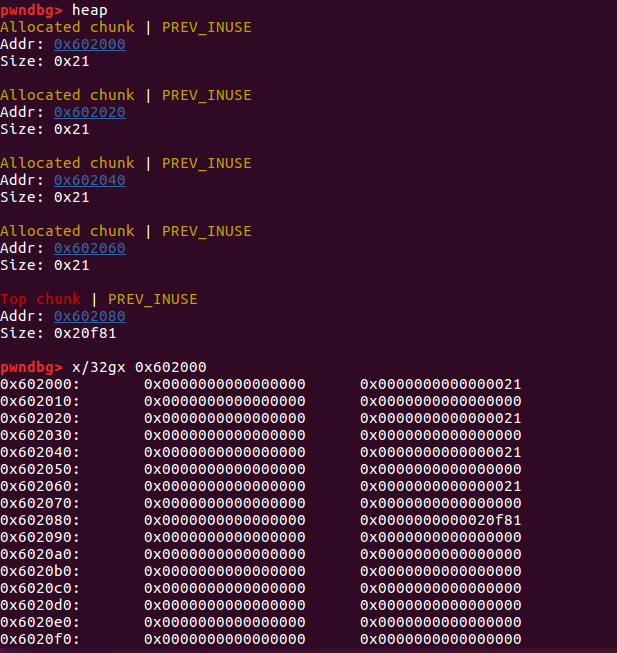
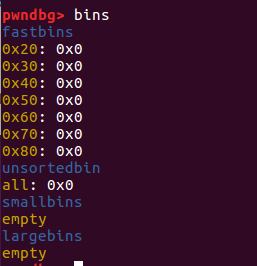
🌰1:对 inuse 的 fastbin 进行 extend
就是通过更改第一个堆块的信息来控制它之后的堆块的内容
1 | |
两次 malloc 后堆块中的数据是这样的
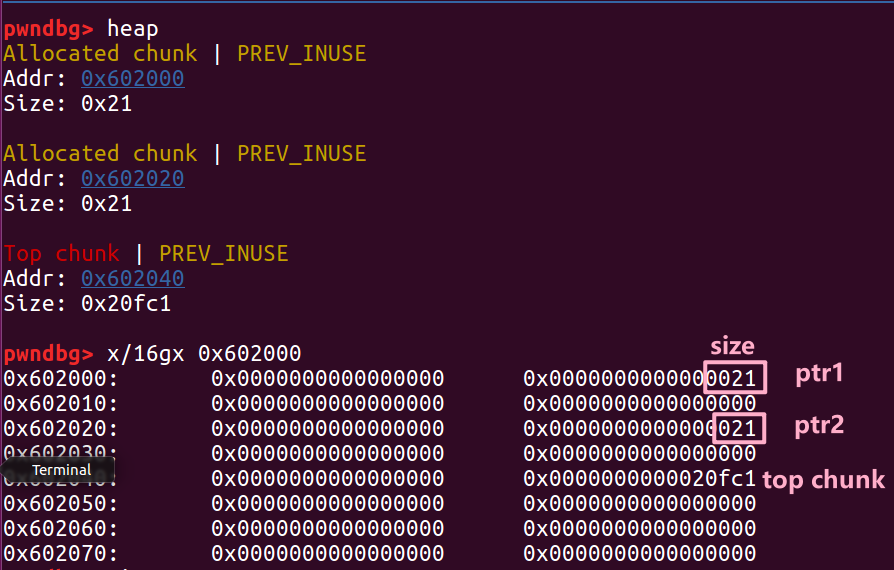
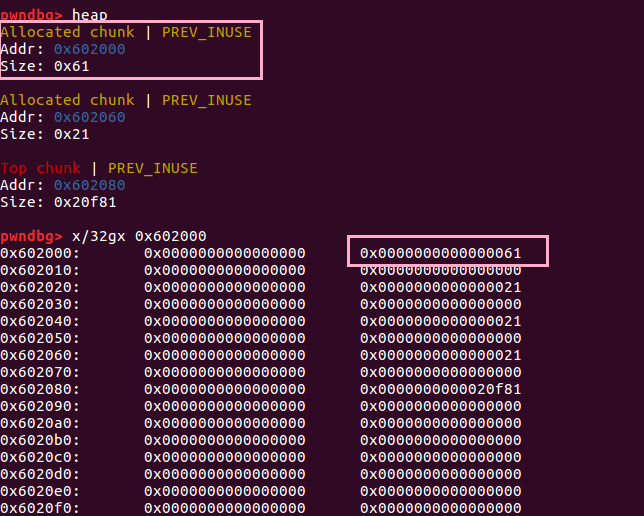
修改了 ptr1 的 size 位后对应变成了 41
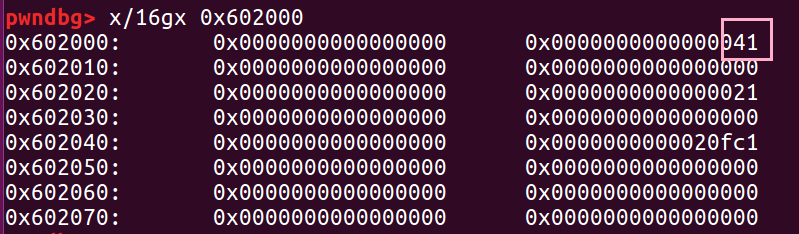
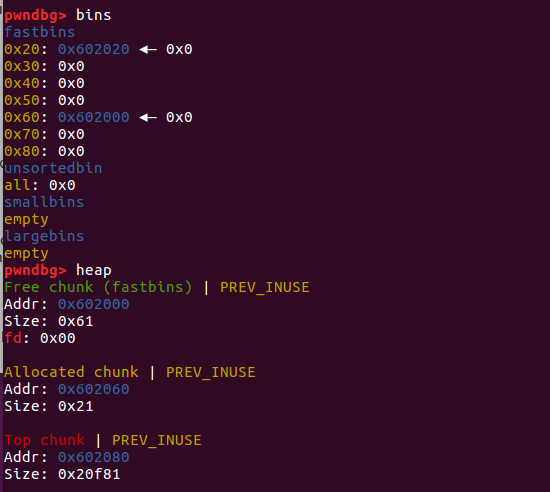
我们 free 掉它之后, 也对应进入了 0x40 的 bin 中
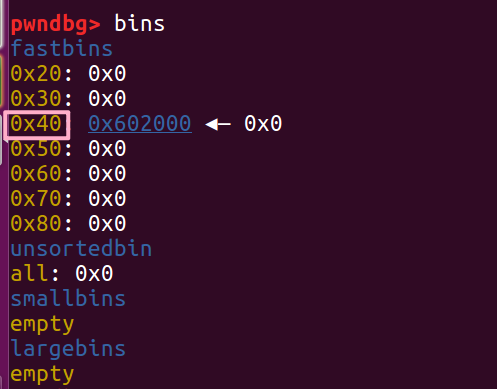
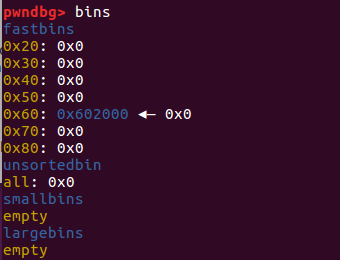
此时我们再次分配 0x30 的堆块就会把原本属于 ptr2 头部的内存分配到 ptr3 中,
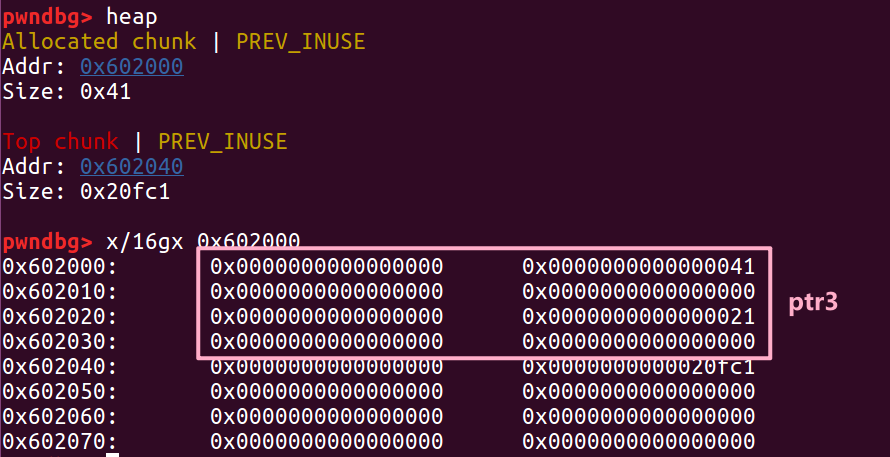
此时原本 chunk2 的头部是现在 ptr3 的用户内容,我们可以直接控制其内容,这种状态就叫做 overlapping chunk。
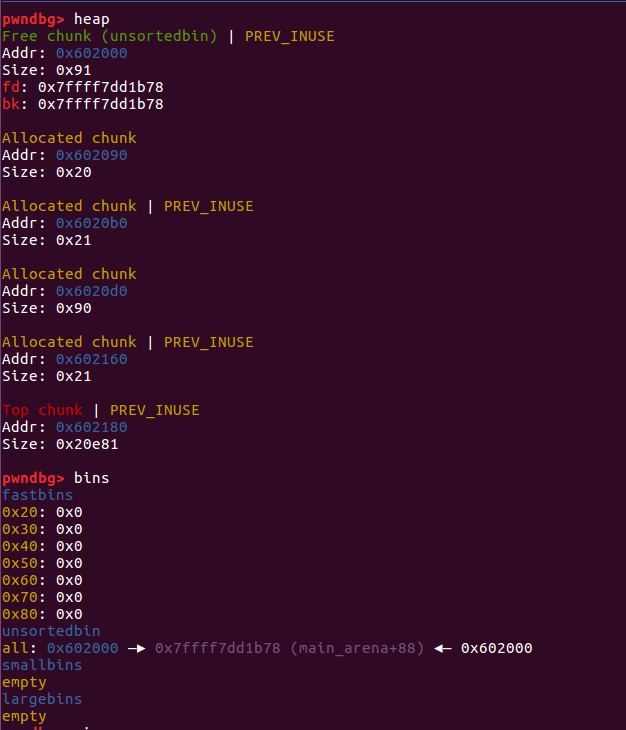
🌰2:对 inuse 的 unsortedbin 进行 extend
我们知道处于 fastbin 范围的 chunk 释放后会被置入 fastbin 链表中,而不处于这个范围的 chunk 被释放后会被置于 unsorted bin 链表中。
接下来我们就使用 0x80 来分配堆。
1 | |
在这个例子中,因为分配的 size 不处于 fastbin 的范围,因此在释放时如果与 top chunk 相连会导致和 top chunk 合并。所以我们需要额外分配一个 chunk,把释放的块与 top chunk 隔开。
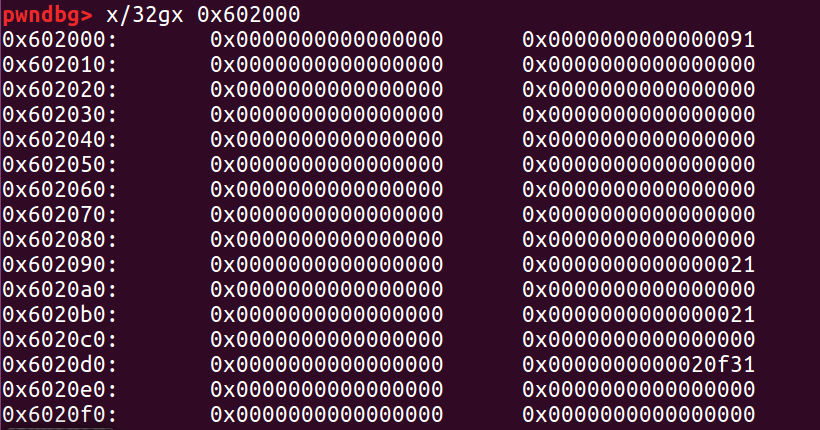
三次 malloc 分配完以后,内存中的数据如下:

修改size 数据后ptr1 和 ptr2 合并,如下:

相应的 free 后进入了 unsorted bin

再次分配我们就达到了overlapping chunk的目的。
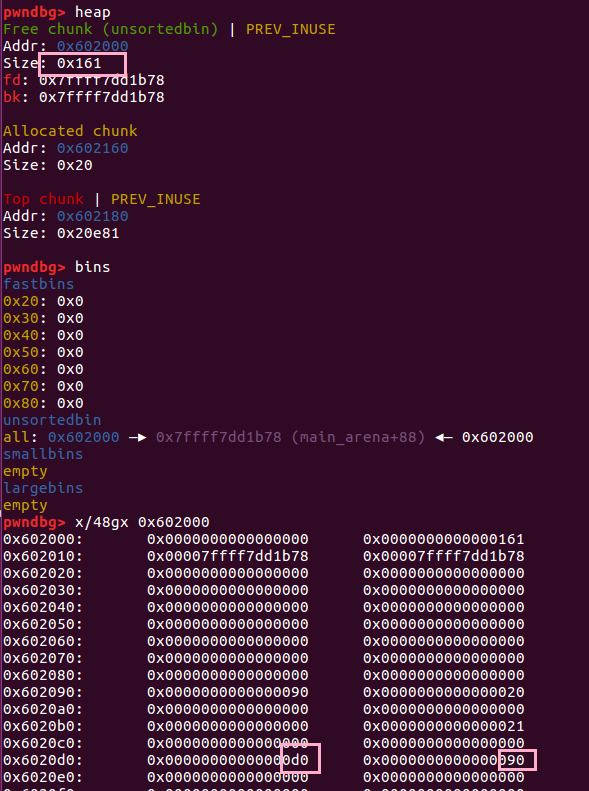
🌰3:对 free 的 unsortedbin 进行 extend
在例二的基础上进行,先释放 chunk ,再修改
1 | |
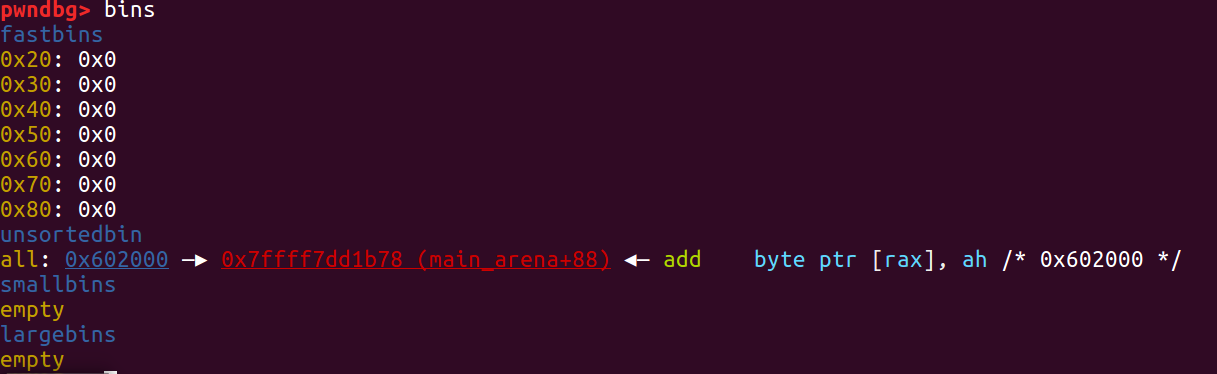
三次 malloc 之后的结果如下
释放 ptr1 后,chunk 进入 unsortedbin
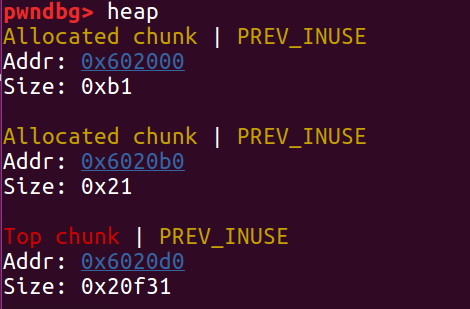
修改 size 字段

再次分配,ptr2 头部被分配进新的堆块,我们就这样控制了 ptr2 的内容
🌰4:通过 extend 向后 overlapping
1 | |
在 malloc(0x50) 对 extend 区域重新占位后,其中 0x10 的 fastbin 块依然可以正常的分配和释放,此时已经构成 overlapping,通过对 overlapping 的进行操作可以实现 fastbin attack。
就像上面的例子,我们在两次free后可以发现bin 中出现了overlapping。
第一轮的 malloc 结束
修改 ptr1 的 size
两次 free,bin 中出现了overlapping。
而接下来的两次 malloc ,“ 两块 ” chunk 也被一次分配了
🌰5:通过 extend 向前 overlapping
前向 extend 利用了 smallbin 的 unlink 机制,通过修改 pre_size 域可以跨越多个 chunk 进行合并实现 overlapping。
1 | |
第一次free后的堆结构如下
对数据进行修改后 free(ptr4) 可以发现 chunk 被合并了
unlink
unlink 机制的存在是为了防止内存过度碎片化。当一个 chunk 被释放时,该 chunk 非 fastbin 或 tcache bin ,libc 就会检查该堆块前后是否有 chunk 属于被释放的状态,如果存在,就会将他们从 bin 中取出进行合并,即使这些前后的堆块是在 fast bin 或者 tcache bin 中。
原理
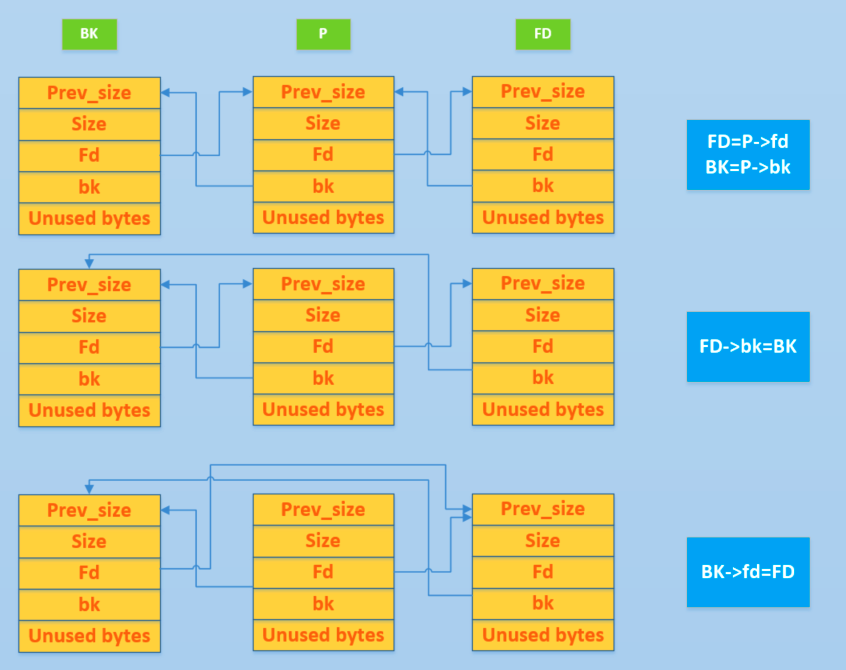
unlink 的过程就类似于把双向链表中间的空闲 chunk 取出来,具体流程如下:
最初 bin 中的堆块像最上图那样链接,P 是我们释放的堆块, BK 是 P 对应链表前方的堆块, FD 是后面的堆块。unlink 结束后就变成了最下图,此时p 在 FD 的 data 中,然后 BK 和 FD 直接相连。
我们先从已经被淘汰的防护时的 unlink 开始学习其原理
被淘汰的 unlink
我们假设堆内的结构如以下左图,现在有物理空间连续的两个 chunk(Q,Nextchunk),其中 Q 处于使用状态、Nextchunk 处于释放状态。

那么如果我们通过某种方式(比如溢出)将 Nextchunk 的 fd 和 bk 指针修改为指定的值。则当我们 free(Q) 时,会依次进行下面的操作:
- glibc 判断这个块属于 small chunk
- 判断是否需要向前合并,发现前一个 chunk 处于使用状态,不需要向前合并
- 判断是否需要向后合并,后一个 chunk 空闲,需要合并
- 进行 unlink 操作
unlink 具体执行的效果如下:
FD = P->fd = target addr - 12,即将 FD 字段赋值为堆块 P 的 fd 字段所存储的数据 target addr - 12BK = P->bk = expect value,即将 BK 字段赋值为堆块 P 的 bk 字段所存储的数据 expect value (我们预期改写的数据)。FD->bk = BK,即将 target addr - 12 + 12 处的内容( target addr 本身)设置为 expect value。BK->fd = FD,即将 expect value + 8 处的内容设置为 target addr - 12。
在这里我们需要确保 expect value + 8 处的地址具有可写的权限,否则可能无法成功利用该漏洞。
成功执行 unlink 漏洞利用后,会将目标地址处的值设置为我们预期的内容,从而实现任意地址写操作。
我们可以利用这个漏洞来将某个 GOT 表项指向系统函数或者我们想要调用的函数,从而劫持程序执行流程。但是需要注意的是,expect value + 8 处的值也会被破坏,可能会影响程序的正常执行,因此在利用漏洞时需要仔细考虑和处理这些影响。
当前的 unlink
哈哈哈,怎么会这么简单呢🤪
现在的 unlink 实现之前会对 chunk 的 size 和双向链表进行检查 ,具体代码如下:
1 | |
其中就有对 fd 和 bk 的检查。而上面的情况中,就会被检查出来,我们无法使用这种方法。
但是我们可以伪造堆块来绕过检查😎,我们有一个公式:
- P -> fd -> bk == P <=> *( P -> fd + 0x18 ) == P
- p -> bk -> fd == P <=> *( p -> bk + 0x10 ) == P
简单点说就是:
- P -> fd = & P - 0x18
- P -> bk = & P - 0x10
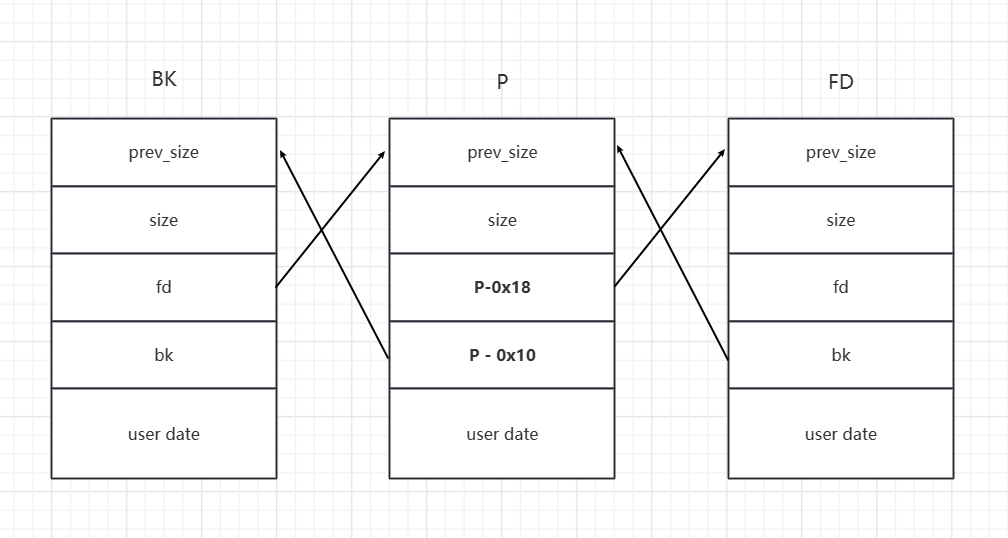
触发unlink后P处的指针会变为 P-0x18 。
如果将上面说的P变为我们想要修改的地址比如保存指针的数组地址,利用上面说到的 unlink 就能控制数组中的指针,并且我们使指针保存类似 free_got、puts_got 等,之后我们修改指针使其为 system_got ,那么下次我们调用其他函数就会调用 system()。
Use After Free
Use After Free 就是内存块被释放以后再次被利用,有以下几种情况:
- 内存块被释放后,其对应的指针被设置为 NULL,再次利用时程序就会崩溃
- 内存块被释放后,其对应的指针没有被设置为 NULL ,而且然后在它下一次被使用之前,没有代码对这块内存块进行修改,那么程序可以正常运转。
- 内存块被释放后,其对应的指针没有被设置为 NULL,但是在它下一次使用之前,有代码对这块内存进行了修改,那么当程序再次使用这块内存时,就很有可能会出现问题。
我们一般所指的 Use After Free 漏洞主要是后两种。此外,我们一般称被释放后没有被设置为 NULL 的内存指针为 dangling pointer (它的中文翻译叫迷途指针😊)。
它的实际应用就是我们在像是 chunk extend 里面用到的示例2
1 | |
Tcache attack
这一部分我的环境是Ubuntu18 libc2.27
简述
Tcache 全名为 Thread Local Caching,在 libc2.26 之后才出现。它为每个线程创建一个缓存,里面包含了一些小堆块。
Tcache bin 是单链表的数据结构,存储相同大小的空闲堆块,size大小范围是 0x20-0x410,允许存放的 chunk 数为7。当你使用 free() 函数释放一个堆块时,glibc 会将该堆块放入适当大小类别的 Tcache bin 中,以备后续再次分配。Tcache bin 采用先进后出的策略,且 prev_inuse 位不会被合并,也就是说 tcache bin 中的 chunk 不会被合并。
攻击方式
在有了 tcache 机制以后,无论是分配还是释放堆块,tcache 都是首先被利用的,直到达到每一中 bin 的上限 7 为止。还有一种情况就是 fast bin 或者 small bin 返回了一个堆块,且 tcache 对应大小的 bin 中未满的话,那么该fast bin 或者 samll bin 链中的堆块会被加入到对应 tcache bin 中直至其上限。
绕过 Tcache
Tcache 机制无非就是增加了一层缓存,绕过 Tcache 就是我们手动构造填充堆块填满某一个大小对应的 thcache bin 链表,使得在再次回收的 bin 进入unsorted bin 或者 small bin,large bin 等等,再利用这些 bin 得到 libc 基址。
原理大致如下:
1 | |
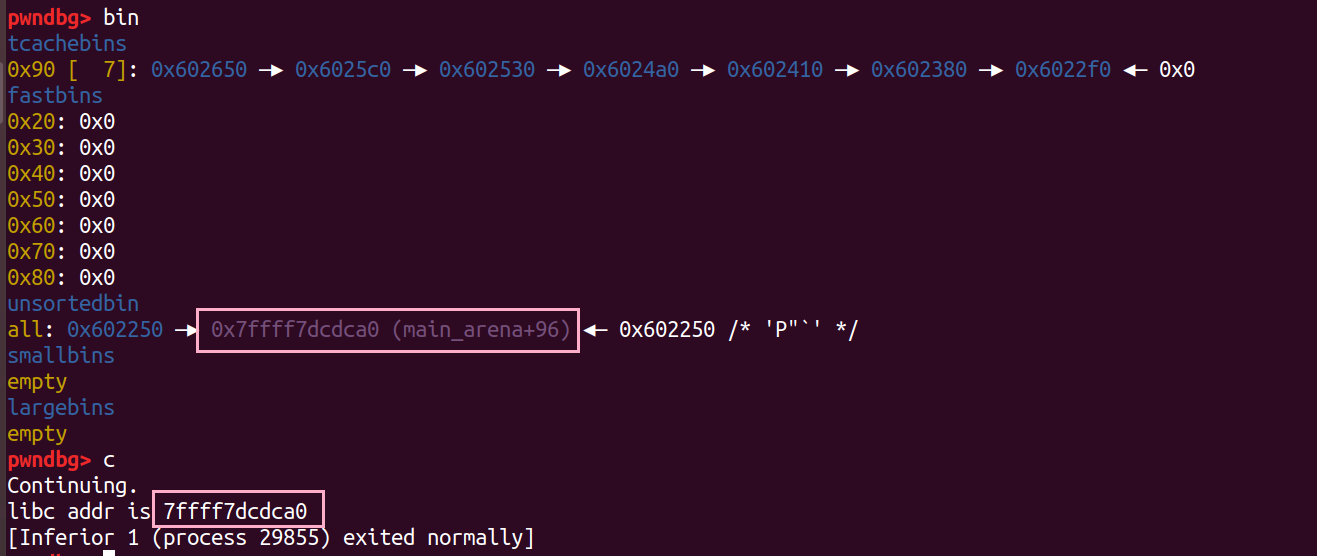
如上我们就泄露出了 main_arena 的地址,接下来就可以通过ret2libc时用到的套路泄露libc基址进而调用目标函数啦。
分配堆到指定的地址
在堆的利用中,我们经常会需要把堆的指针分配到我们想要的地址上去,比如BSS段或者直接指向栈空间实现程序流的操控,抑或是将堆块重新分配。
我们可以通过以下几种方法实现:
tcache poisoning
tcache poisoning的利用思路如下:
分配一个目标大小的堆块,再将其释放
利用堆溢出等漏洞,将刚刚释放的堆块的某个指针(例如
fd或bk)修改为我们可控的地址指针(如__free_hook或__malloc_hook等局部变量的地址)。再次建立相同大小的堆块并释放,这样该堆块的内容会被认为是一个有效的 tcache 链表节点。
再次建立相同大小的堆块,此时 tcache 会将之前填充的目标指针地址作为返回值返回给调用者,我们可以在这段地址内写入攻击代码,程序执行到目标地址,就可以实现任意代码执行。
因为 fd 指针会返回空闲堆块地址给程序,而这个地址被我们替换成了目标地址,所以实际上返回值是目标地
原理大致如下:
1 | |

tcache house of spirit
tcache house of spirit 这种利用方式是由于 tcache_put() 函数检查不严格导致的,在释放的时候没有检查被释放的指针是否真的是堆块的 malloc 指针,我们就可以伪造一个 fake_chunk 来跳转到目标地址。
利用思路是伪造一个 size 符合 tcache bin size 的 fake_chunk ,使程序在释放时误以为他们属于 tcache 的管理范围,就实现了任意地址的目的的。
原理大致如下:
1 | |

泄露地址
在做堆题时,经常会遇到保护全开的情况,特别是地址随机化保护PIE,或者题目本身没有明显可利用的打印函数,这时就需要采取一些机制来泄露出libc地址或者堆地址等。
泄露libc地址
泄露 libc 利用的就是 bin 中双向链表的性质,当一个堆块被加入链表时,它的 fd 和 bk 指针会指向 libc 中的地址。在“绕过 tcache”中我们就是利用了这个特性来泄露的 libc 地址。
还有更加直接的方法,只需要让分配和释放的chunk 大于等于 0x410字节(超过 tcache 的范围)即可。需要注意的是,这时我们需要防止释放的堆块和 top chunk 合并。
原理大致如下:
1 | |
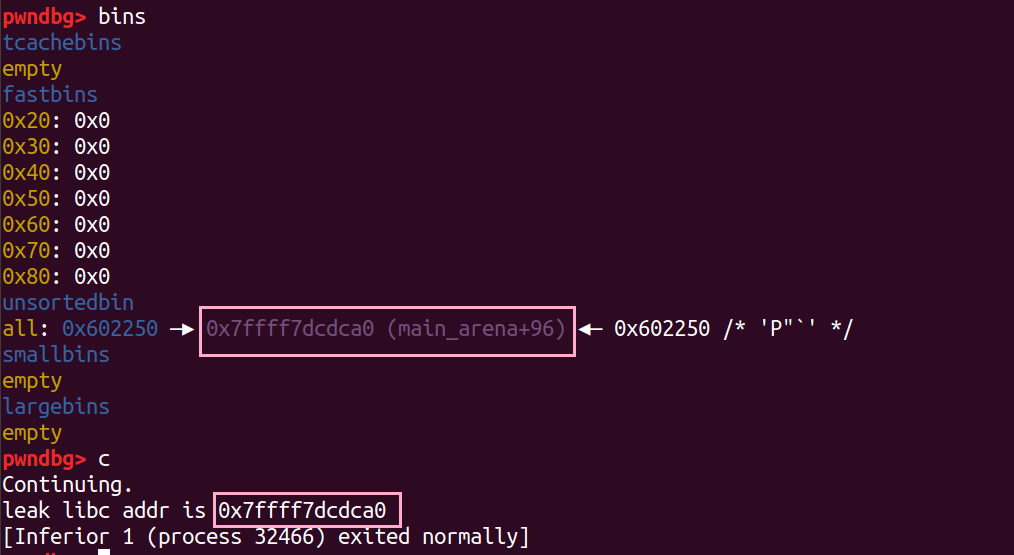
泄露 heap 地址
除了泄露 libc 地址,我们还可以泄露 heap 地址。在泄露堆地址以后,我们确定好目标地址的偏移,再通过修改 tcache bin 的 fd 指针,就可以在下次分配时分配到我们想要的堆块。
在 libc-2.28 中,增加了对 tcache 二次释放的检查,所以此种攻击方法在 libc-2.28 及其更高版本中失效
原理大致如下:
1 | |
double free 错误提示了,换了三个版本的 Libc 都木有用,先放着碰到题目再说🫥
还有另一种方法,我们利用 malloc 不会清除内存空间的特性以及 printf 格式化字符串遇到字符 “\x00” 才会停止的特性去泄露 heap base 。
题目示例:
1 | |
exp:
1 | |

利用 tcache bin 记录堆块泄露地址
有的时候题目会限制free的次数,我们无法通过多次释放来填满 tcache bin 。这种情况我们就可以结合 tcache bin 的特性。我们知道,在初始化堆的时候, tcache bin 会生成一块 0x250 大小的堆块来记录属于 tcache bin 大小的堆块信息。我们修改这里的记录,就可以把后续释放的堆块放进 unsorted bin 中。
方法一:
1 | |
上方代码中,我们通过利用 double free 让一个堆块自身构成循环,然后 malloc 3次后就可以让 tcache bin 的记录变为 -1,由于 libc 源代码是认定为无符号整型所以此时也就是一个非常大的数,自然也就认为该 tcache bin 是被填满了的。最后再 free 相同大小的堆块,就会被释放到相应的bin中。
方法二:
直接修改记录信息。利用double free泄露出heap地址,计算偏移并求出记录该tcache bin的地址,然后利用tcache bin poison将堆块分配到这里进行修改。
1 | |
上方代码中我们将记录块修改为0x07这样就会被认为是已经填满了七块堆块,下一个 free 掉的堆块就会进入相应的区域。
tcache extend
其实就是我们可以通过释放堆块后对其数据进行修改。其中由于tcache机制的加入使得漏洞利用更简单。chunk extend 也更加的轻松,只需要修改当前chunk的size,我们free再malloc后就可以获得对应大小的chunk。
1 | |

Fastbin attack
这一部分我的环境是 ubuntu16 libc2.23
简单回顾一下 fast bin 的特性:
- 属于fast bin 的 chunk 大小在 64 位下是 0x20-0x80,每一条 bin 链表以 0x10 递增,共计七条链;32 位是 0x10-0x40 ,以 0x8 递增。
- fast bin 是单链表且先进后出,就是说在 fast bin 中只有 fd 指针会被使用。
- 属于 fast bin 的 chunk 被释放时不会被 unlink ,不会和堆块进行合并,即使紧邻 Top chunk。
fast bin posioning
其实和之前 tcache 的方法是一样的,只不过我们现在的环境是 libc2.23 没有 tcache😊
这种攻击方法的目的就是将堆块分配到我们想要控制的内存区域,再通过题目所给的编辑堆块的功能来修改这一部分的内存区域。
实现攻击目标,首先要在目标区域为造出一个堆块,将伪造堆块的size大小设置为要申请的chunk大小+0x10,然后将伪造堆块的地址填入对应大小的bin链中,之后正常申请堆块即可。
大致原理如下:
1 | |

如上代码,我们修改了 fd 指针,使得 fd 指针指向了 ptr[0]。这样我们再次分配大小为 0x10 的堆块时,会从被修改的 fd 指针指向的地址处获取堆块,并返回给我们。

因为我们写入到 fd 指针的是 fck 的地址,也就是伪造堆块的头地址,而 malloc 返回的是用户数据地址,所以两个地址相差0x10
fast bin house of spirit
House of Spirit 这种技术的核心在于在目标位置处伪造 fastbin chunk,并将其释放,从而达到分配指定地址的 chunk 的目的。
我们需要注意的是,系统对 chunk 会有相应的检查,我们需要绕过检查。相关数据如下:
fake chunk 的 IS_MAPPED 不能为 1
这个标志位位于size低二比特位。标志位是 1 代表堆块由 mmap 分配,而 mmap 分配的堆块不进入 fast bin 管理。
地址对齐
比如32位程序的话fake_chunk的prev_size所在地址就应该位
0xXXXX0或0xXXXX4。64位的话地址就应该在0xXXXX0或0xXXXX8。大小对齐
需要满足 fsat bin 的尺寸要求,大小不能大于0x80。
next chunk 的大小不能小于 2 * SIZE_SZ,同时也不能大于 av->system_mem
最大不能超过 av->system_mem ,即 128kb。next_chunk 的大小一般我们会设置成为一个超过 fast bin 最大的范围的一个数,但要小于 128kb,这样做的目的是在 chunk 连续释放的时候,能够保证伪造的 chunk 在释放后能够挂在 fast bin 中 main_arena 的前面,这样以来我们再一次申请伪造 chunk 大小的块时可以直接重启伪造 chunk。
不能构成 double free 的情况
fake_chunk前一个释放块不能是fake_chunk本身,如果是的话_int_free函数就会检查出来并且中断
1 | |

我们在 gdb 里面走一遍
首先分配 fake chunk ,我们查看该地址的内存信息(我编译的时候开了保护所以每一次运行的地址不一样)

在执行完赋值操作以后就变成了这样

double free
所谓 double free 就是同一个堆被分配两次,其实不仅仅是两次也可以是多次,也就是说被释放的 chunk 在 fast bin 中出现多次。这样之后我们可以从 fast bin 链表中取出同一个堆块,结合堆块的数据内容可以实现类似于类型混淆的效果啦。 同样,因为两次释放的同一个堆块会将指针指向自己,所以我们也可以用来泄露 heap 的地址。
double free 能够成功的原因主要有两部分:
- fast bin 的堆块被释放以后 next_chunk 的 prev_inuse 位不会被清空
- fast bin 在执行 free 的时候仅仅验证了 main_area 直接指向的块,即链表指针头部的块。
演示说明:
1 | |

我们分别在每一次的 free 和 malloc 处下断点,gdb 中的流程如下:
第一次 free ptr1,ptr1的地址进入 fast bin
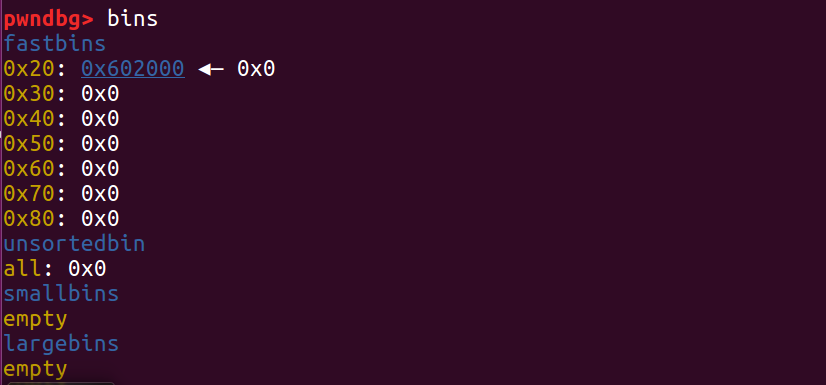
第一次 free ptr2,ptr2 的地址进入 fast bin ,此时 ptr1 的 fd 指针指向 ptr2
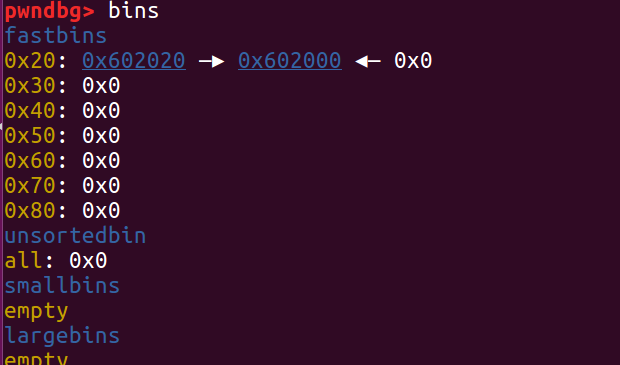
第二次 free ptr1,此时 ptr2 的 fd 指针指向 ptr1,ptr1 的 fd 指针仍然指向 ptr2
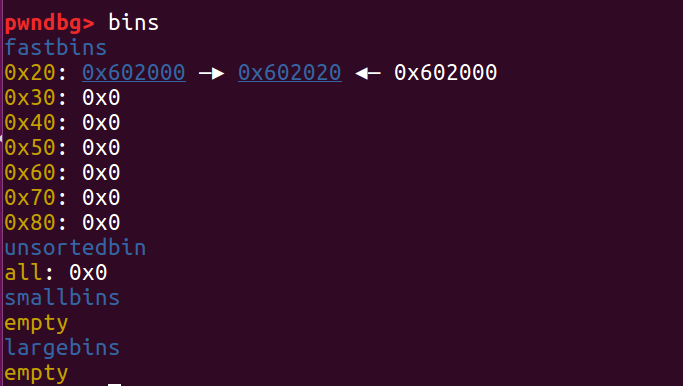
第一次 malloc,最后进的 ptr1 被分配出去
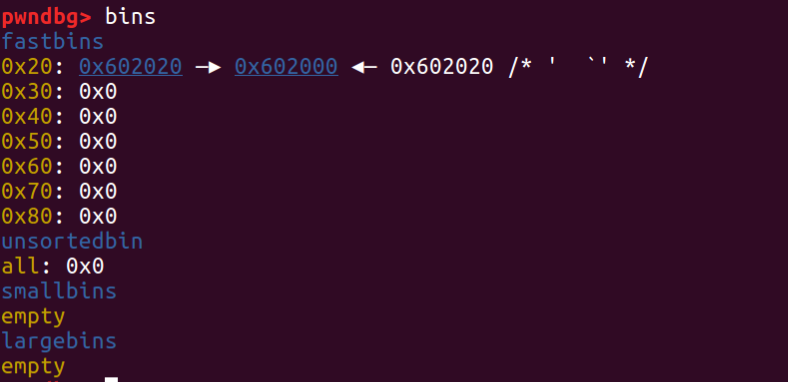
第二次 malloc, ptr2 被分配出去,但因为因为 ptr2 的 fd 指针指向 ptr1,所以系统仍然认为 ptr1 在 fast bin 中,位置在 ptr2之后(这个图是我们对 ptr1进行了一些 fd 混淆的操作之后截的所以 ptr1 的指针指向 stack)
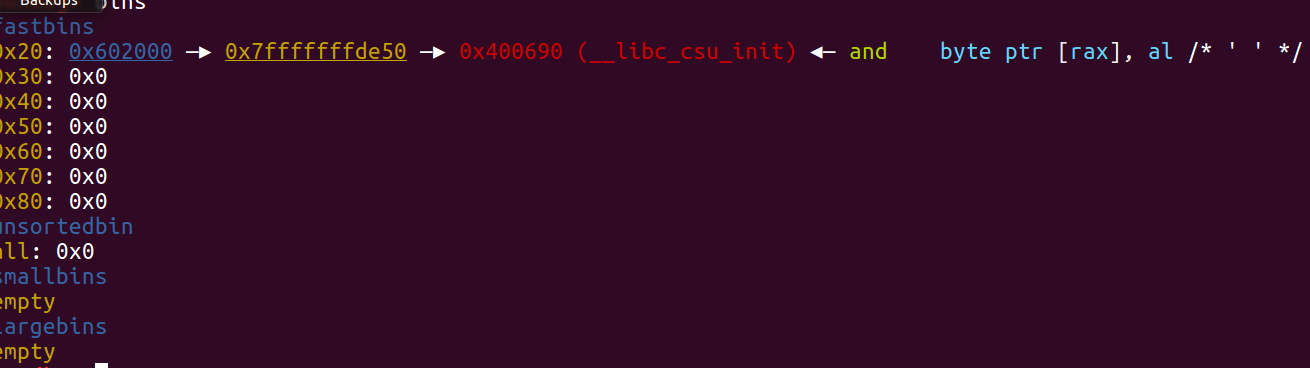
第三次malloc就会把 ” 系统以为仍然在fast bin 里 “ 的 ptr1分配出去。
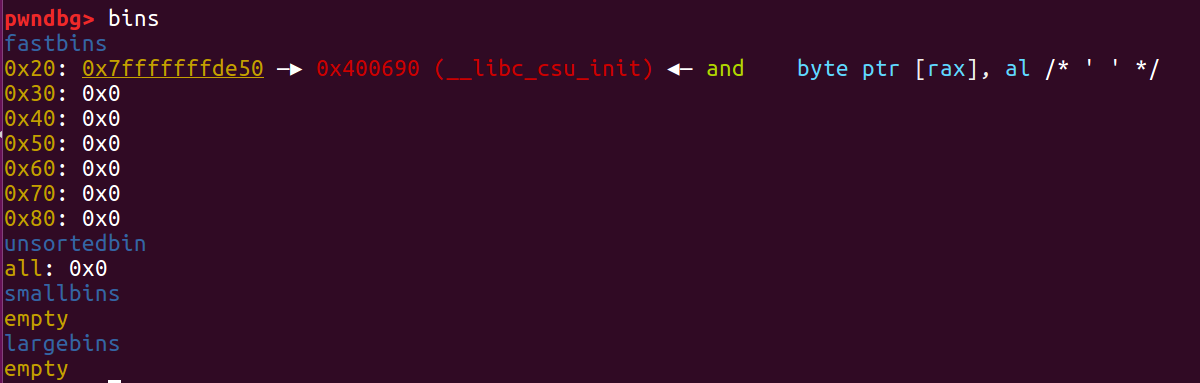
最后再一次malloc,就会把我们改写后的地址分配给堆啦
Unsortedbin attack
简单回顾一下 unsortedbin 的基本来源和使用情况:
来源
- 当一个比较大的 chunk 被分为两个部分之后,如果剩下的部分大于 minsize ,就会被放到 unsorted bin 中。
- 释放一个不属于 fast bin 的 chunk ,并且这个 chunk 不和 top chunk 紧邻,这个 chunk 就会被放进 unsorted bin 中
- 当进行 malloc_consolidate 时,如果不是和 top chunk 近邻的话,可能会把合并后的 chunk 放到 unsorted bin 中。
Unsorted Bin Leak
unsorted bin 采用 FIFO,即先进后出的顺序释放,也就是说从 unsortedbin 中取堆块的时候是从尾部取所以 unsorted bin 使用 bk 指针遍历堆块
1 | |
gdb 中的调试是这样的:
free 之后的堆结构及内存
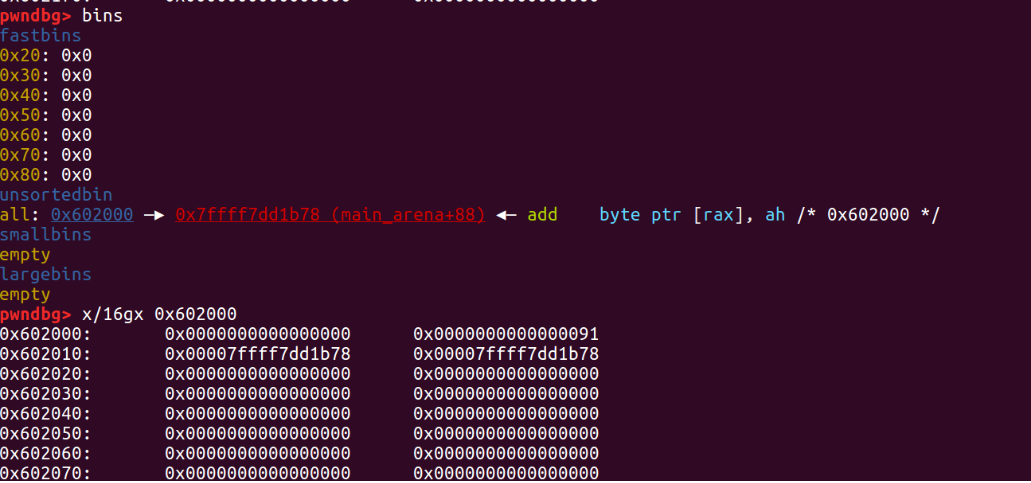
如果你运行了上面的代码,就会发现 unsorted bin 中只有一个 chunk 时,bin 的 fd 指针和 bk 指针都指向 main_arena 。同样,如果有多个,头部 bin 的 fd 会指向 main_arena 。

main_arena 和 __malloc_hook 的地址差是 0x10,而大多数的 libc 都可以直接查出 __malloc_hook 的地址。以 pwntools 为例
1 | |
这样就可以获得 main_arena 与基地址的偏移了。
Unsorted Bin Attack 原理
在 _int_malloc 中由一段与 bk 指针有关的代码,当将一个 unsorted bin 取出的时候,会将 bck->fd 的位置写入本 Unsorted Bin 的位置。
1 | |
unsorted_chunks (av) 用于获取 unsortedbin 双向链表头部的指针
unsorted_chunks (av) 的两个重要元素:
fd:bin [0](指向下一块数据,这里指向 unsorted bin 链表的头部)
bk:bin [1](指向前一块数据,这里指向 unsorted bin 链表的尾部)
unsorted bin 从尾部依次往前遍历,由于遍历到一个 chunk 就会进行脱链,所以如果要访问到下一个 chunk,只需要访问 unsorted_chunks (av)->bk 就可以了,而且当 bk 内容为 unsorted_chunks (av) 则可以说明全部数据已经被遍历,unsortbin 无内容了。
代码的后两行在做的就是把 victim 中链表中移除。在这个过程中,就利用 bck->fd = unsorted_chunks (av); 往上面写了一个 unsorted_chunks (av) 的地址,这是一个在 libc 上的地址,由 0x7f 开头,是一个很大的数字。
也就是说我们如果控制了 bck ,那么就可以在脱链的过程中,往 victim->bk->fd 写入一个很大的数字。
1 | |
具体流程如下图
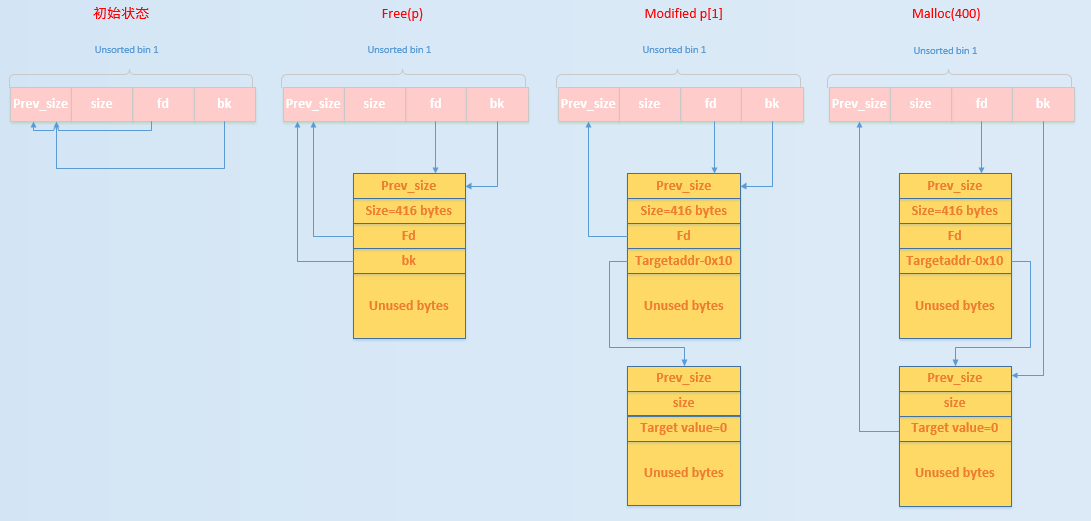
初始状态的时候,unsorted bin 的 fd 和 bk 均指向 unsorted bin 本身。
执行 free(p) ,释放的 chunk 进入 unsortedbin
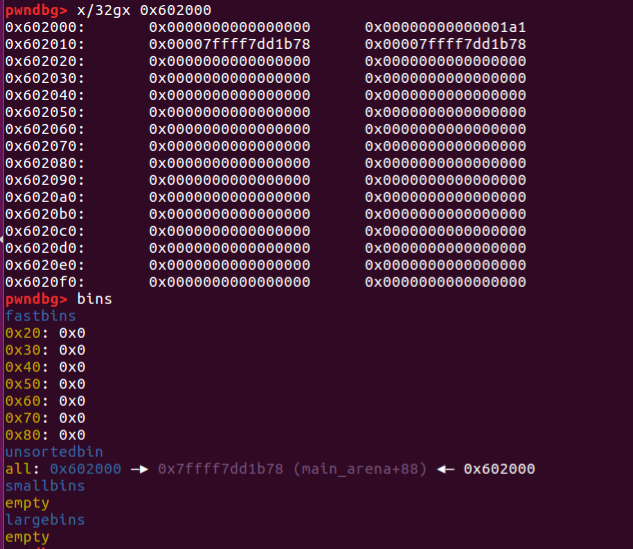
修改 p[1] 之后,原来在 unsorted bin 中的 p 的 bk 指针就会指向 target addr-16 处伪造的 chunk,即 Target Value 处于伪造 chunk 的 fd 处。
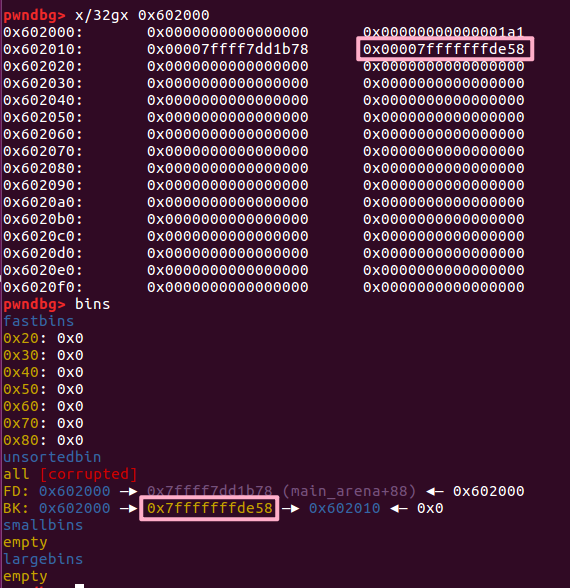
再次申请 chunk,就会从 unsortedbin 中取出,此时 unsortedbin 中的结构变成
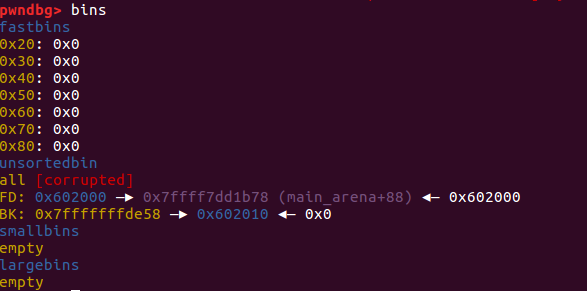
最后结果如下

Largebin attack
搞这里的时候头昏昏的,先这么放着,待修改😶🌫️
largebin 复习
大于512(1024)字节的 chunk 称为 large chunk,large bin 就是用于管理这些 large chunk
被释放进 Large Bin 中的 chunk ,除了和其他的 bin 相同的 prev_size、size、fd、bk 这几个结构之外,还具有 fd_nextsize 和 bk_nextsize :
- fd_nextsize 指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针
- bk_nextsize 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针
一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样可以避免在寻找合适 chunk 时挨个遍历,提高了工作效率。
排列顺序:
按照大小顺序从小到大排序
如果大小相同就按照 free 的先后顺序排序
多个大小相同的堆块,只有首个堆块的 fd_nextsize 和 bk_nextsize 会指向其他堆块,后买你堆块的这两个指针均为0。size 最大的堆块的 bk_nextsize 指向最小的堆块,size 最小的堆块的 fd_nextsize 指向最大的堆块
示例
1 | |
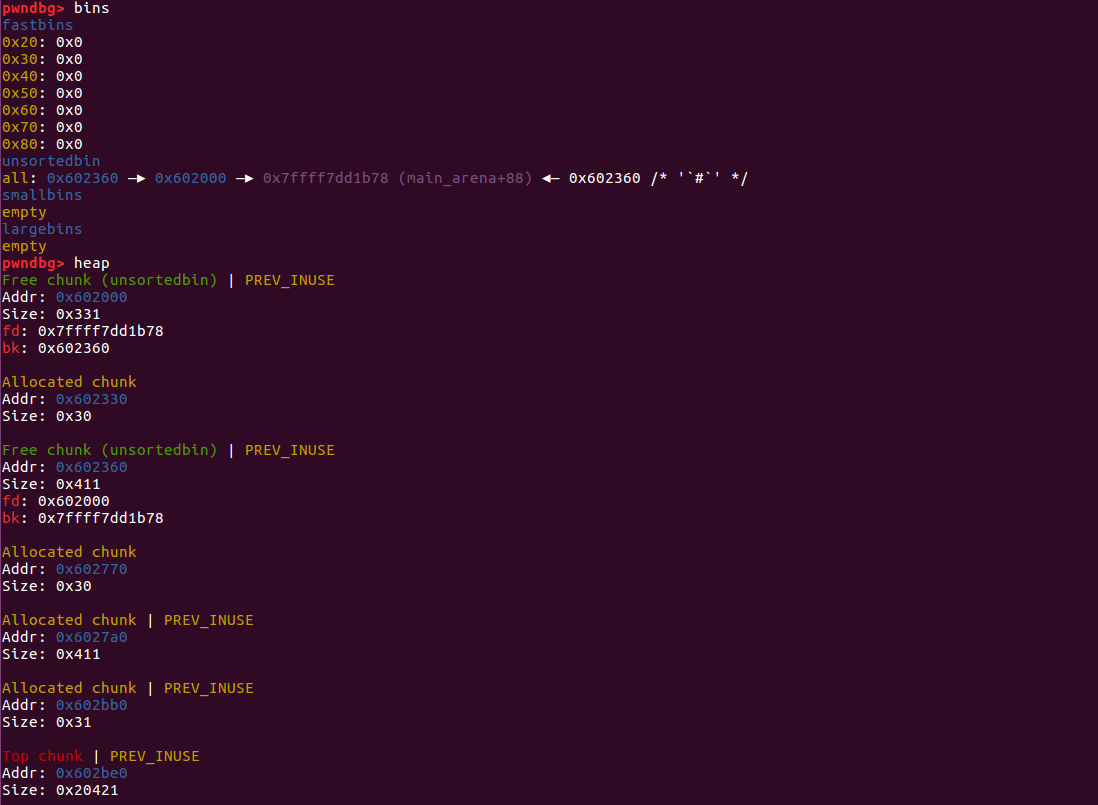
第一轮 malloc 结束,堆结构如下,p1、p2、p3 的地址分别是 0x602000 、 0x602360 、 0x6027a0
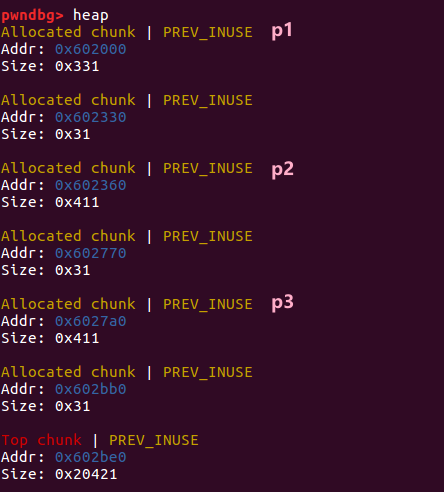
释放掉 p1 和 p2,两个堆块都进入 unsortedbin 中 ,要注意的是,p1 的大小是 0x330 大小属于 small bin,而 p2 的大小是 0x410 属于 large bin
用 malloc(0x90); 分割堆块,所以原本的堆块被分割,剩余的部分进入了 largebin 。
实际上详细的流程如下:
- 从 unsorted bin 中拿出最后一个 chunk(p1 属于 small bin 的范围)
- 把这个 chunk 放入 small bin 中,并标记这个 small bin 有空闲的 chunk
- 再从 unsorted bin 中拿出最后一个 chunk(p2 属于 large bin 的范围)
- 把这个 chunk 放入 large bin 中,并标记这个 large bin 有空闲的 chunk
- 现在 unsorted bin 为空,从 small bin (p1)中分配一个小的 chunk 满足请求 0x90,并把剩下的 chunk(0x330 - 0xa0)放入 unsorted bin 中
所以会出现下图的堆结构:unsorted bin 中有一个 chunk 大小是 0x330 - 0xa0 = 0x290 ;large bin 某一个序列的 bin 中有一个 chunk 大小是 0x410
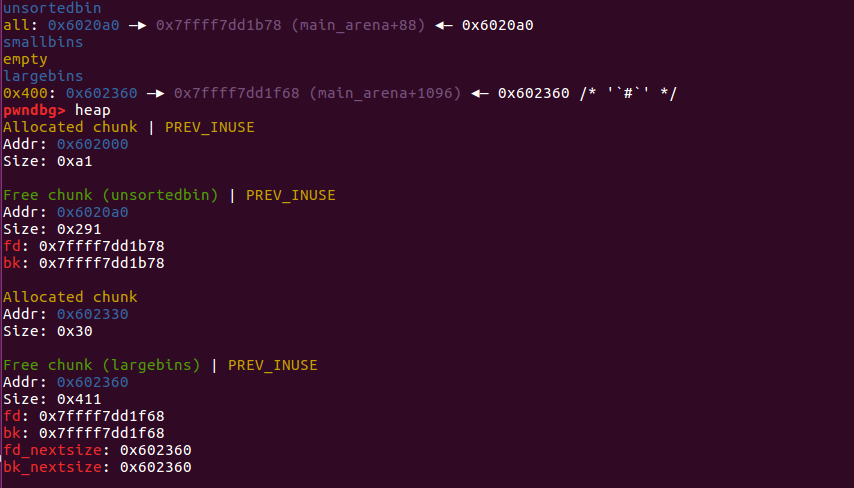
free 掉 p3 ,p3 进入 unsortedbin
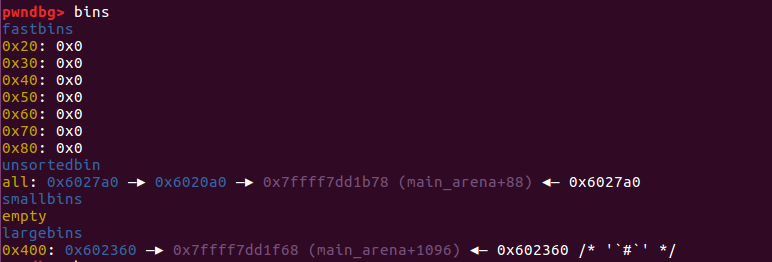
接下来修改 p2 的信息,修改前后依次如下图


修改后的结果如下:
| size | fd | bk | fd_nextsize | bk_nextsize |
|---|---|---|---|---|
| 0x3f1 | 0 | stack_var1_addr - 0x10 | 0 | stack_var2_addr - 0x20 |
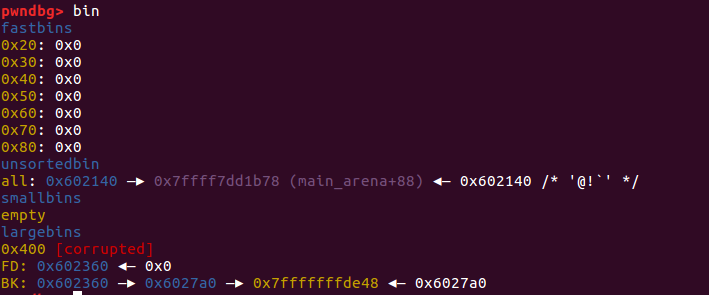
我们记这个 stack_var1 - 0x10 为 fakechunk1,此时 stack_var1 - 0x10 的 fd 指针指向 fakechunk1 ,同时 stack_var2 - 0x20 为 fakechunke2 ,此时 stack_var2 - 0x20 的 fd 指针指向 fakechunk2。
接下来我们再次 malloc(0x90), p3 挂进了 largebin
具体有关这个部分的 malloc 代码如下:
1 | |
这次我们从 unsortedbin 中拿出的是属于 largebin,所以进入到堆块大小判断的 else 分支,接下来就是指针的操作,由于我们的 p3 被我们修改过数据,就会跳过 while 的循环,进入下面的部分分支
1 | |
所以在下面的代码中,我们被修改的指针就完成了利用,修改了 stack_var1 和stack_var2 的值。
觉得堆题还是要去分析一下源码,接下来就计划去看看源码
先做几道题练练手