在PWN的边缘疯狂试探
一点点 pwn 基础——栈和堆、汇编基础和Linux常用保护机制
介绍
PWN是一个黑客语法的俚语词 ,是指攻破设备或者系统 。发音类似”砰”,对黑客而言,这就是成功实施黑客攻击的声音–砰的一声,被”黑”的电脑或手机就被你操纵了 。
(上文来自百度)
个人认为解决PWN题就是利用简单的逆向得到代码,从代码中发现漏洞,再通过二进制或系统调用等方式利用这些漏洞获得目标主机的shell 。
很酷!!!!!😎
前知知识
就是我只知道这么多就来学pwn了
寄存器
寄存器是CPU内部用来存放数据的一些小型存储区域,用来暂时存放参与运算的数据和运算结果。
我们常常看到 32位 CPU、64位 CPU 这样的名称,其实指的就是寄存器的大小。
Intel 32位体系结构(简称IA32)处理器包含8个四字节寄存器,如下图所示:

在大多数情况下,上图所示的前6个寄存器均可作为通用寄存器使用。
编译器会根据操作数大小选择合适的寄存器来生成汇编代码。在汇编语言层面,这组通用寄存器以%e(AT&T语法)或直接以e(Intel语法)开头来引用.
例如mov $5, %eax或mov eax, 5表示将5赋值给寄存器eax。
不同架构的CPU,寄存器名称被添加不同前缀以指示寄存器的大小。例如x86架构用字母“e”作名称前缀,指示寄存器大小为32位;x86_64架构用字母“r”作名称前缀,指示各寄存器大小为64位。
栈溢出
栈溢出就是数据会占用一个存储空间,但是我们写代码的时候默认输入数据就是符合规定的数据,并没有对输入数据进行限制,这时超出这个空间大小的数据就会输入到合法空间以外的地方并造成破坏。
借此我们就可以控制这个不允许用户操作的空间内的寄存器,改变寄存器的值达到代码执行的效果。
通过寻找危险函数,我们快速确定程序是否可能有栈溢出,以及有的话,栈溢出的位置在哪里。常见的危险函数如下
输入:
- gets,直接读取一行,忽略’\x00’
- scanf
- vscanf
输出:
- sprintf
字符串:
- strcpy,字符串复制,遇到’\x00’停止
- strcat,字符串拼接,遇到’\x00’停止
- bcopy
Linux的一些基础命令
sudo :SuperUserDo 在需要权限的命令前使用
apt-get:可以执行安装、升级、甚至移除软件这类任务
grep:配合正则表达式食用,用于寻找文件或内容
cat:查看文件
rm:移除文件,还可以使用**-r**来进行递归移除,从而移除整个文件夹
cp:拷贝文件
ls:查看目录下的文件
暂时只想起这么多
汇编基础
pwn 研究二进制还是要学习底层计算机语言的😢
汇编语言是二进制指令的文本形式,与指令是一一对应的关系。比如,加法指令00000011写成汇编语言就是 ADD。
堆和栈
段
一般情况下,程序都是由bss段,text段和date段三个段组成。
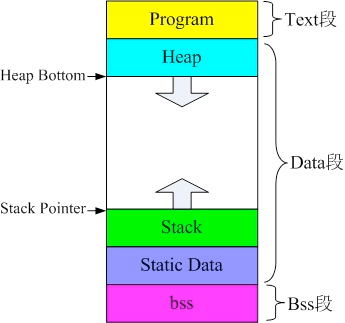
bss 段:只有定义而没有赋初值的全局变量和静态变量。
data 段:存放在编译阶段 (而非运行时) 就能确定的数据,可读可写。就是通常所说的静态存储区,存储赋了初值的全局变量和赋初值的静态变量以及常量。
text 段:放程序代码,在编译时确定,只读。
.bss段
bss段是用来存放未初始化的全局变量和静态变量的一块内存区域,一般在初始化时bss段部分会清零。
.text段
存放程序代码的区域,在编译时确定,只读。
更进一步讲是存放处理器的机器指令,当各个源文件单独编译之后生成目标文件,经连接器连接各个目标文件并解决各个源文件之间的函数引用。与此同时,还要将所有目标文件中的.text段合在一起,但不是简单的将他们“堆”在一起,还要处理各个段之间函数引用问题。
.date段
用于存放在编译阶段(而非运行时)就能确定的数据,可读可写。也是通常所说的静态存储区,赋了初值的全局变量,常量和静态变量都存放在这个区域。
Heap-堆
程序运行的时候,操作系统会给它分配一段内存,用来储存程序和运行产生的数据。这段内存有起始地址和结束地址,比如从0x1000到0x8000,起始地址是较小的那个地址(低位),结束地址是较大的那个地址(高位)。
程序运行过程中,对于动态的内存占用请求(比如新建对象,或者使用malloc命令),系统就会从预先分配好的那段内存之中,划出一部分给用户,具体规则是从起始地址开始划分。
实际上,起始地址会有一段静态数据,这里忽略
举例来说,用户要求得到10个字节内存,那么从起始地址0x1000开始给他分配,一直分配到地址0x100A,如果再要求得到22个字节,那么就分配到0x1020。

这种因为用户主动请求而划分出来的内存区域,就叫做 Heap(堆)。它由起始地址开始,从低位向高位增长。Heap 的一个重要特点就是不会自动消失,必须手动释放,或者由垃圾回收机制来回收。
Strack-栈
Stack 是由于函数运行而临时占用的内存区域。Stack 是由内存区域的结束地址开始,从高位向低位分配。每一次函数执行结束,就自动释放一个帧,所有函数执行结束,整个 Stack 就都释放了。
比如,内存区域的结束地址是0x8000,第一帧假定是16字节,那么下一次分配的地址就会从0x7FF0开始;第二帧假定需要64字节,那么地址就会移动到0x7FB0。
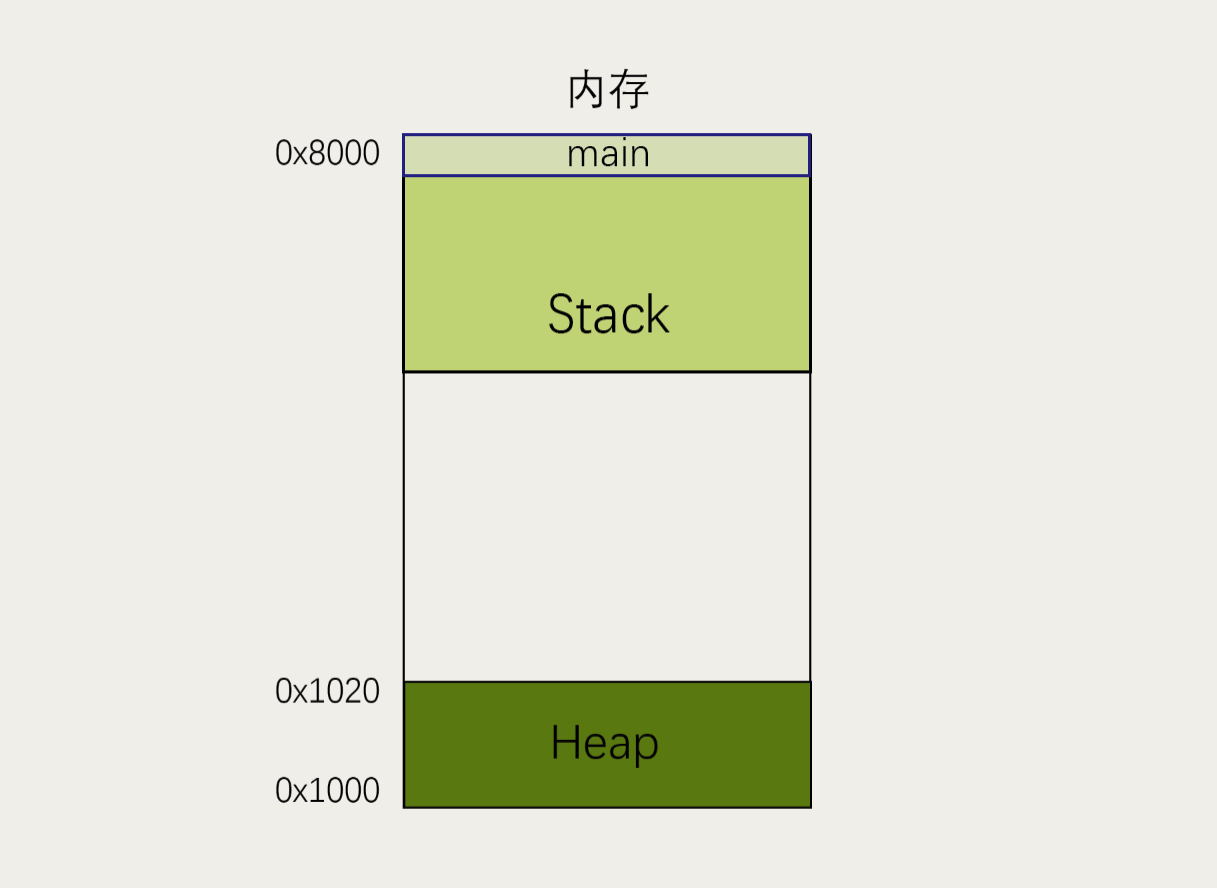
举个具体的🌰:
1 | |
上面代码中,系统开始执行main函数时,会为它在内存里面建立一个帧(frame),所有main的内部变量(比如a和b)都保存在这个帧里面。
当调用其他函数时,程序运行到这一行,会新建一个帧。此时存在两个帧:main和add_a_and_b。一般来说,调用栈有多少层,就有多少帧。
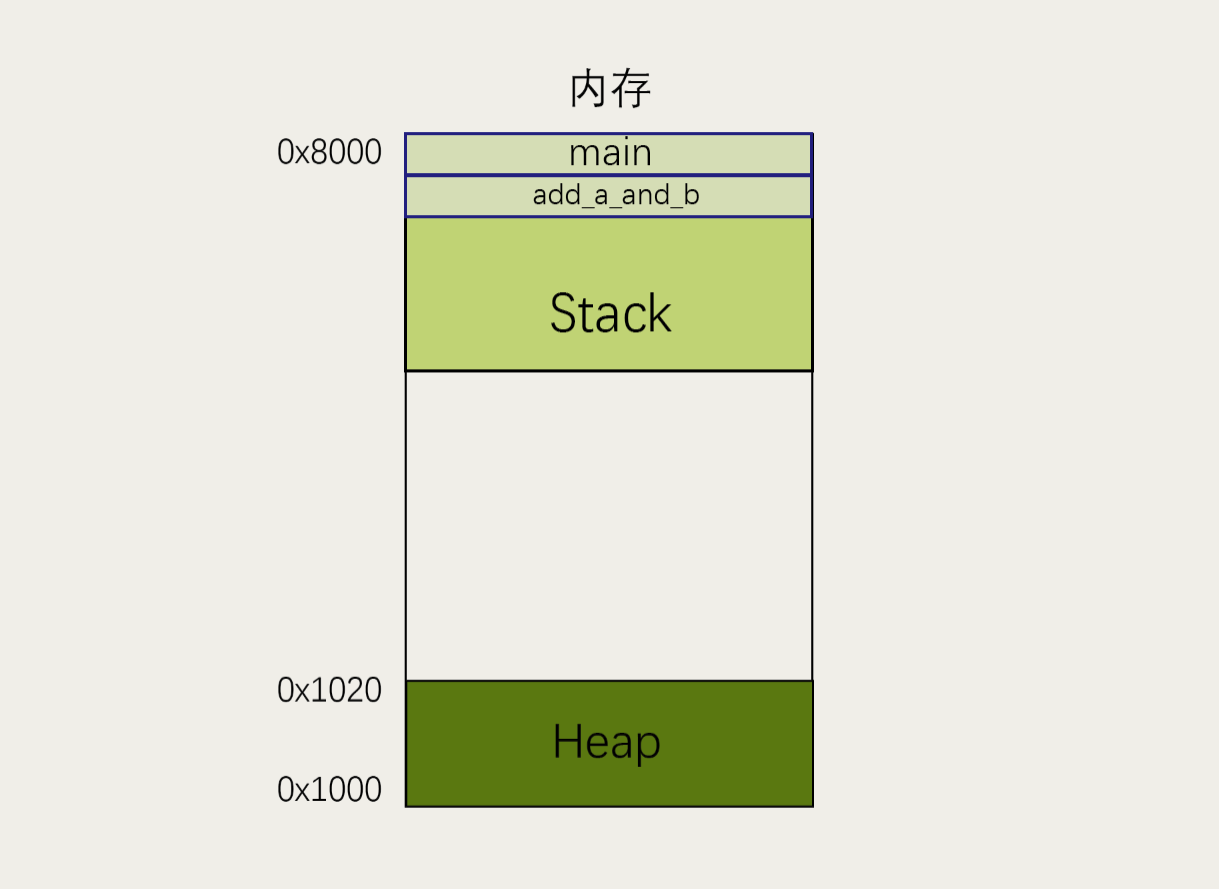
等到add_a_and_b运行结束,它的帧就会被回收,系统会回到函数main刚才中断执行的地方,继续往下执行。
生成新的帧,叫做”压栈”,英文是 push;栈的回收叫做”出栈”,英文是 pop。Stack 的特点就是,最晚入栈的帧最早出栈(因为最内层的函数调用,最先结束运行),这就叫做”后进先出“的数据结构。每一次函数执行结束,就自动释放一个帧,所有函数执行结束,整个 Stack 就都释放了。通过这种机制,就实现了函数的层层调用,并且每一层都能使用自己的本地变量。
一个🌰
1 | |
将其转换为汇编语言就是
1 | |
以我现在的水平还不是很能看明白,我就是把文件全复制下来了
简化以后主要就是这些内容:
1 | |
可以看到原程序两个函数add_a_and_b和main对应上面的两个标签_add_a_and_b和_main,每个标签里面是该函数所转成的 CPU 运行流程,每一行就是 CPU 执行的一次操作。
以其中一行为例:
1 | |
这一行里面,push是 CPU 指令,%ebx是该指令要用到的运算子。一个 CPU 指令可以有零个到多个运算子。
基础指令
| 汇编指令 | 实际作用 | 等价代码 |
|---|---|---|
| mov rax,rbx | 用于赋值 | rax=rbx |
| add/sub rax,rbx | 用于加/减法 | rax+=rbx/rax-=rbx |
| and/xor/or rax,rbx | 用于与/异或/或 | rax&=rbx/rax^=rbx/rax |
| push rax | 压栈 | rsp-=8;*rsp=rax |
| pop rax | 出栈 | rax=*rsp;rsp+=8 |
| call rax | 调用函数 | push rip;jmp rax; |
| ret | 从函数返回 | pop rip; |
| cmp rax,rbx | 比较两个数。不保留结果,只修改flags寄存器 | rax-rbx |
| test rax,rbx | 比较两个数。不保留结果,只修改flags寄存器 | rax&rbx |
跳转指令
| 汇编指令示例 | 英文全称 | 实际作用 |
|---|---|---|
| jmp | jump | 跳转 |
| jz | jump if zero | 为0时跳转 |
| jnz | jump if not zero | 不为零时跳转 |
| jg | jump if greater | 有符号数大于跳转 |
| jl | jump if lsee | 有符号数小于跳转 |
跳转指令不同于 mov 指令,他可以用于修改段寄存器 cs、ip 的值,从而修改 CPU 在内存中所读取的内容的地址。
表格是从小卓的博客copy来的
Linux常用保护机制
操作系统提供了许多安全机制来尝试降低或阻止缓冲区溢出攻击带来的安全风险。在编写漏洞利用代码的时候,需要特别注意目标进程是否开启了 保护机制
checksec
这不是个保护机制是个脚本软件。
checksec用来检查可执行文件的属性,查看文件开启了哪些保护机制。
1 | |
以之前一道 Pwn 题题目为例: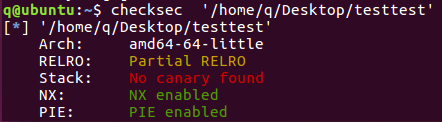
RELRO
介绍
RELRO即为read only relocation,可以理解为我们熟悉的windows系统里的只读。
设置符号重定向表格为只读或在程序启动时就解析并绑定所有动态符号,从而减少对 GOT(Global Offset Table)攻击。
参数设置
1 | |
CANNARY(栈保护)
介绍
栈溢出保护是一种缓冲区溢出攻击缓解手段,当函数存在缓冲区溢出攻击漏洞时,攻击者可以覆盖栈上的返回地址来让 shellcode 能够得到执行。
原理
当启用栈保护后,函数开始执行的时候会先往栈里插入 cookie 信息,当函数真正返回的时候会验证 cookie 信息是否合法,如果不合法就停止程序运行。攻击者在覆盖返回地址的时候往往也会将 cookie 信息给覆盖掉,导致栈保护检查失败而阻止 shellcode 的执行。
在 Linux 中我们将 cookie 信息称为 canary。
参数设置
1 | |
NX(DEP)
介绍
NX 即 No-eXecute(不可执行),NX(DEP)的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入 shellcode 时,程序会尝试在数据页面上执行指令,此时 CPU 就会抛出异常,而不是去执行恶意指令。
参数设置
gcc 编译器默认开启了 NX 选项,如果需要关闭 NX 选项,可以给 gcc 编译器添加 - z execstack 参数。
1 | |
PIE
介绍
PIE即Position-Independent Executable( 位置无关可执行文件),与ASLR 技术类似。
ASLR 将程序运行时的堆栈以及共享库的加载地址随机化,而 PIE 技术则在编译时将程序编译为位置无关,即程序运行时各个段(如代码段等)加载的虚拟地址也是在装载时才确定。
这就意味着,在 PIE 和 ASLR 同时开启的情况下,攻击者将对程序的内存布局一无所知,传统的改写GOT 表项的方法也难以进行,因为攻击者不能获得程序的.got 段的虚地址。
liunx 下关闭 PIE 的命令如下:
1 | |
参数设置
1 | |
杂七杂八忙了一个周,抽时间学了这么点东西。我是菜鸡🥬
有看几道pwn题,发现大部分题目都是需要一些逆向技巧的,有些还会和web结合 非常疯狂
如果有空web一些基础的东西我还是会继续学的,就熬夜吧熬夜吧🤪