INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */ INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
structmalloc_chunk* fd;/* double links -- used only if free. */ structmalloc_chunk* bk;
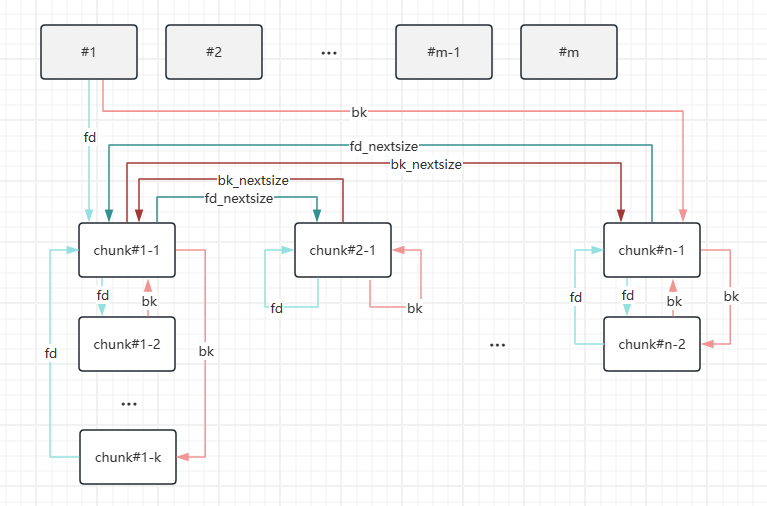
/* Only used for large blocks: pointer to next larger size. */ structmalloc_chunk* fd_nextsize;/* double links -- used only if free. */ structmalloc_chunk* bk_nextsize; };
large bin 一共有 63 个,从 small bin 最小不能表示的 chunk 开始,大到无穷。
large bin 从 128*SIZE_SZ 开始。那么下标为0的large bin表示的范围就是128*SIZE_SZ~144*SIZE_SZ(左闭右开),同理下标为1的large bin表示的范围就是144*SIZE_SZ~160*SIZE_SZ,以此类推,等到32的时候就在原来的基础上加32*SIZE_SZ作为右开区间
/* Retry with another arena only if we were able to find a usable arena before. */ //可以理解为一个错误检验?如果 chunk 为空,但分配区指针不为空,再次调用 _int_malloc 获取 if (!victim && ar_ptr != NULL) { LIBC_PROBE (memory_malloc_retry, 1, bytes); ar_ptr = arena_get_retry (ar_ptr, bytes); victim = _int_malloc (ar_ptr, bytes); }
staticvoid * _int_malloc (mstate av, size_t bytes) { INTERNAL_SIZE_T nb; /* normalized request size */ unsignedint idx; /* associated bin index */ mbinptr bin; /* associated bin */
mchunkptr victim; /* inspected/selected chunk */ INTERNAL_SIZE_T size; /* its size */ int victim_index; /* its bin index */
mchunkptr remainder; /* remainder from a split */ unsignedlong remainder_size; /* its size */
unsignedint block; /* bit map traverser */ unsignedint bit; /* bit map traverser */ unsignedintmap; /* current word of binmap */
mchunkptr fwd; /* misc temp for linking */ mchunkptr bck; /* misc temp for linking */
constchar *errstr = NULL;
checked_request2size (bytes, nb);
/* There are no usable arenas. Fall back to sysmalloc to get a chunk from mmap. */ if (__glibc_unlikely (av == NULL)) { void *p = sysmalloc (nb, av); if (p != NULL) alloc_perturb (p, bytes); return p; }
//确认用户申请的 chunk 大小不属于 smallbin if (!in_smallbin_range (nb)) { bin = bin_at (av, idx);
/* skip scan if empty or largest chunk is too small */ //如果 largebin 不为空,用户请求的 size 小于 large bin 中最大的 chunk size if ((victim = first (bin)) != bin && (unsignedlong) (victim->size) >= (unsignedlong) (nb)) { //while 循环获取刚好小于用户请求的 size 的 large bin victim = victim->bk_nextsize; while (((unsignedlong) (size = chunksize (victim)) < (unsignedlong) (nb))) victim = victim->bk_nextsize;
/* Avoid removing the first entry for a size so that the skip list does not have to be rerouted. */ if (victim != last (bin) && victim->size == victim->fd->size) victim = victim->fd;
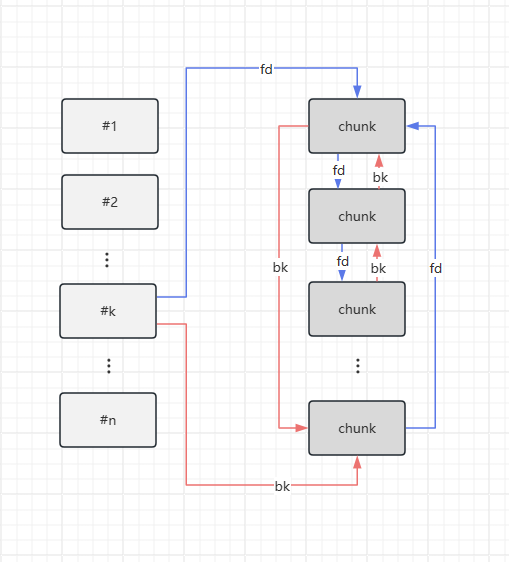
在处理切割下来的堆块时,它只检测了了 unsorted bin->fd->bk 是否等于那个 unsorted bin ,对于堆块来说就是只检测了 bk 指针。这是一个利用小技巧,也就是说这时我们可以修改 fd 指针为期望的值,不会在这里被检测到,就是 unsorted bin attack 了。
被切割的剩下 chunk 会被放在 unsortedbin ,但是程序仍然会检测它是不是在 small bin 的范围里。如果不在 small bin 范围内,就会清空它的 fd_nextsize 和 bk_nextsize 。因为它要回到 unsorted bin ,这两个字段就没什么用了,就会被清空。
如果当前的 large bin 中没有符合要求的 chunk,则在其它 size 的 large bin 中进行查找。首先需要看一下这个 binmap 结构:
1 2 3 4 5
++idx; bin = bin_at (av, idx); block = idx2block (idx); map = av->binmap[block]; bit = idx2bit (idx);
这个结构用于快速检索一个 bin 是否为空,每一个 bit 表示对应的 bin 中是否存在空闲 chunk 。这一段就是说,如果 large bin 搜索完了都没有找到合适的 chunk ,那么就去下一个 idx 里面寻找。然后一共有4个 int ,每个 int 32位表示一块 map ,一共表示 128 位。
这段代码的执行流程就是:利用 idx 索引值来获取指向对应 bin 的指针。然后根据这个 bin 指针来获取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
for (;; ) { /* Skip rest of block if there are no more set bits in this block. */ if (bit > map || bit == 0) { do { if (++block >= BINMAPSIZE) /* out of bins */ goto use_top; } while ((map = av->binmap[block]) == 0);
bin = bin_at (av, (block << BINMAPSHIFT)); bit = 1; }
两个判断条件:
bit>map:如果这个位的权值都比它整个的 map 都大了,说明 map 上那个 bit 的权值必定为0
bit==0:如果这个 bit 都是 0 说明这个 index 也不对。
两个条件只要满足其一就是没有空闲堆块,接着去查看下一个 index。
接下来的判断如果 map==0 ,说明这整个 block 都没有空闲块,就直接跳过,不为 0 则退出去执行下面的操作,如果超过了 block 的总数,那就说明 unsorted bin 和 large bin 中也没有合适的chunk,那我们就切割top_chunk了,这里用了一个 goto use_top; 跳转,在后面会分析到。
/* Advance to bin with set bit. There must be one. */ // 在 block 中找到存在符合要求的 large bin 链表头指针 while ((bit & map) == 0) { bin = next_bin (bin); bit <<= 1; assert (bit != 0); }
/* Inspect the bin. It is likely to be non-empty */ victim = last (bin);
/* If a false alarm (empty bin), clear the bit. */ // 如果链表非空 if (victim == bin) { av->binmap[block] = map &= ~bit; /* Write through */ bin = next_bin (bin); bit <<= 1; }
经过上面的流程,我们已经找到了合适的 block ,接下来就是寻找 block 的各个位了。从低位开始,如果检查到map那一位对应为0就找下一位,我们前面提到 bk 为 large bin 的最小块,所以先从它开始,也就是先执行 bin = next_bin (bin); 。
当然不能说 map 里面说这里有它就有,我还得自己判断一下这个bin里面是不是真的有,如果没有就要及时把标志位清除然后 bit<<1 去寻找下一个 index 。
/* When we are using atomic ops to free fast chunks we can get here for all block sizes. */ //如果大小不满足需要,就先合并所有的 fastbin,接着执行之前的循环 elseif (have_fastchunks (av)) { malloc_consolidate (av); /* restore original bin index */ if (in_smallbin_range (nb)) idx = smallbin_index (nb); else idx = largebin_index (nb); }
若用户申请的大小在 fast bin 的范围内,则考虑寻找对应 size 的 fastbin chunk ,如果这个对应 size 的 fastbin 中有满足的堆块就返回给用户,如果没有就进入下一步。
如果用户申请的 size 符合 small bin 的范围,则在相应大小的链表中寻找 chunk 。若 small bin 未初始化,则调用 malloc_consolidate 初始化分配器,然后继续下面的步骤;如果已经初始化了,就寻找对应的 small bin 的链表,如果该 size 的 small bin 又满足的堆块就取出返回,否则继续下面的步骤。如果申请的不在 small bin 的范围,那么调用 malloc_consolidate 函数去合并所有 fastbin 并进入下一步。
如果在上面的流程中都没有找到对应的块,会遍历 fast bins 中的 chunk,将相邻的 chunk 进行合并, 并链接到 unsorted bin 中。
如果用户申请的大小符合 large bin 或 small bin 链表为空,完成了上一步之后,就会开始遍历处理 unsorted bin 链表中的 chunk 。如果 unsorted bin 只 有一个 chunk,这个 chunk 在上次分配时被使用过,且所需分配的 chunk 大 小属于 small bin,同时这个 chunk 的 size 大于等于需要分配的大小。这种情况下就直接将该 chunk 进行切割;否则将根据 chunk 的空间大小将其放入 small bins 或是 large bins 中,遍历完成后,转入下一步。
上面的步骤执行结束还没有找到堆块,就说明需要分配的是一块大的内存,或者 small bin 和 unsorted bin 中都找不到合适的 chunk,并且 fast bin 和 unsorted bin 中所有的 chunk 都清除干净了。程序就来时从 large bins 中按照 “smallest-first,best-fit” 的原则,找一个合适的 chunk,从中划分一块所需大小的 chunk,并将剩下的部分链接回到 bins 中。若操作成功,则分配结束,否则转到下一步。
根据 binmap 找到表示更大 size 的 large bin 链表,若其中存在空闲的 chunk ,则将 chunk 拆分之后返回符合要求的部分,并更新 last_remainder。如果没有合适的堆块就进入下一步去 top chunk 中寻找。
若top_chunk的大小大于用户申请的空间的大小,则将top_chunk拆分,返回符合用户要求的chunk,并更新last_remainder 。否则将再一次检查 fast bin,如果 fast bin 不为空,就调用 malloc_consolidate() 合并堆块后再次从第 4 步开始重新查找。
如果前面的步骤中都没有找到合适的 chunk ,才会调用 sysmalloc() 重新分配空间并处理原本的 top chunk 。
我们 free(A) ,第一次 free A,对应的 bin 为空,这个 chunk 链入其中,现在 fast bin 中多了一个 A 。接下来我们第二次 free(A) ,A 会再次被加入 fast bin 中,然后会导致产生一个自己指向自己的指针。这时 fast bin中的情况就是两个A,A->A。此时我们再申请一个和 A 一样大的 chunk ,A 被申请走,但是fast bin 链中还剩下一个 A,但是此时我们手里有一个 A ,fast bin 中也有一个 A 。
这样我们就可以直接编辑 A 的指针域了。比如我让它指向了 got 表中的 free() 函数。那么此时 fast bin 中的情况就是 A->free@got 。然后我再次申请和 A 一样大小的 chunk ,A 被取出来, fast bin 中剩下free@got 。那么我第三次申请就得到了在 free@got 那边的 chunk ,然后假如我偷偷修改一下 free@got 为 system() ,那就能 get shell 了。同时我们可以看到,free@got 这个指针是能任意编辑的,也就是说我想申请到哪都不是问题,这样就能任意地址写了。
/* Lightweight tests: check whether the block is already the top block. */ // 检查当前 chunk 是否是 top chunk 头(防止 double free) if (__glibc_unlikely (p == av->top)) { errstr = "double free or corruption (top)"; goto errout; } /* Or whether the next chunk is beyond the boundaries of the arena. */ // 判断 next chunk 是否超过分配区 if (__builtin_expect (contiguous (av) && (char *) nextchunk >= ((char *) av->top + chunksize(av->top)), 0)) { errstr = "double free or corruption (out)"; goto errout; } /* Or whether the block is actually not marked used. */ // 检查 next chunk 的 inuse 位,判断被释放的 chunk 是否在使用 if (__glibc_unlikely (!prev_inuse(nextchunk))) { errstr = "double free or corruption (!prev)"; goto errout; }
// 如果前面释放的 chunk 大小较大,将 fast bin 合并到 unsortedbin 中 if ((unsignedlong)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) { if (have_fastchunks(av)) malloc_consolidate(av);
// 如果进程的分配区是主分配区,调用 systrim 收缩内存,否则获取非主分配区的 heap_info,用 heap_trim 收缩 heap if (av == &main_arena) { #ifndef MORECORE_CANNOT_TRIM if ((unsignedlong)(chunksize(av->top)) >= (unsignedlong)(mp_.trim_threshold)) systrim(mp_.top_pad, av); #endif } else { /* Always try heap_trim(), even if the top chunk is not large, because the corresponding heap might go away. */ heap_info *heap = heap_for_ptr(top(av));